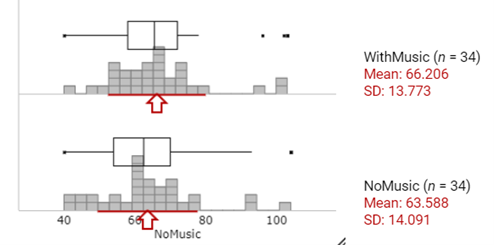
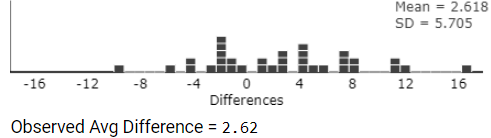
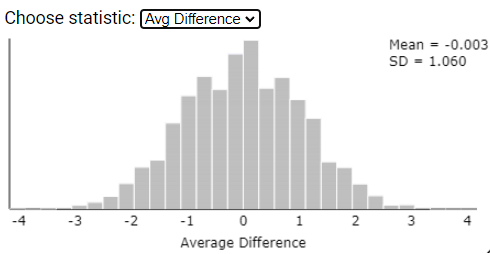
For each participant, we could randomly determine which of their typing speed measurements was measured with music and which without music. To do this, we would flip a coin. If the coin lands heads up, change the sign of the difference (so switch the music and no-music results). If the coin lands tails up, keep the results with their original labels (the difference would not change). Flip the coin for all 34 participants, find the (new) difference for each person and find the mean of these differences,
\(\bar{x}_d\text{.}\) Repeat this "swapping" process a large number of times and look at the distribution of the
\(\bar{x}_d\) values. Then count how many of these simulated
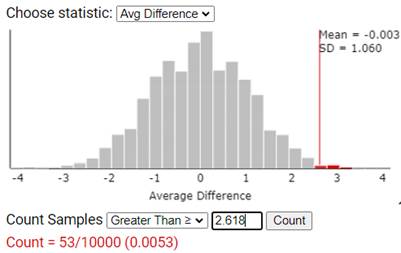
\(\bar{x}_d\) values are at least as extreme as the
\(-2.62\) we observed in our study (where "as extreme" would mean
\(\bar{x} > 2.62\) and
\(\bar{x} \lt -2.62\) for our two-sided alternative).
for i:1 to 1000
for j: 1 to n
multiplier = flip a coin (-1,1) w/ prob 0.5
newdifference[j] = multiplier*olddiff[j]
end loop
calculate meandiff[i]=mean(newdifference)
end loop
pvalue=2*sum(meandiff[i] > 2.62) /1000