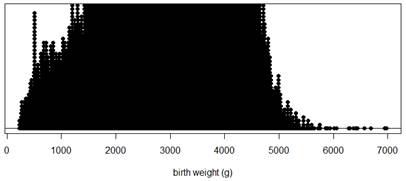
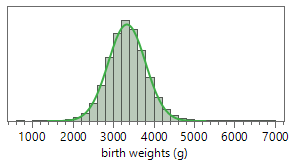
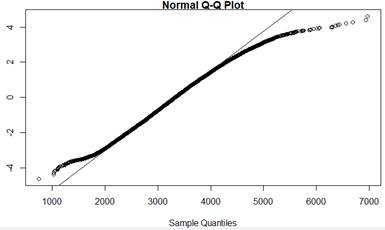
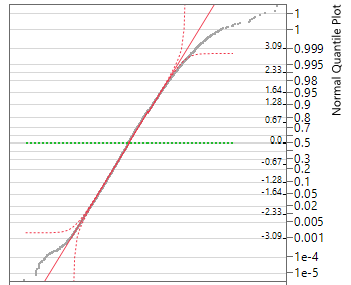
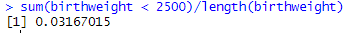1. Representativeness of data.
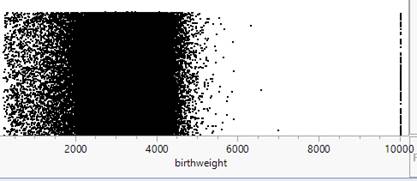
Are these data likely to be representative of birth weights for all 3,638,436 U.S. births in 2024? Explain.
births).
births = read.table("http://www.rossmanchance.com/iscam4/data/USbirthsJan2024.txt",
header=TRUE, sep="\t")
nrow(births) # Check number of observations
# PC:
births = read.table("clipboard", header=TRUE)
# MAC:
births = read.table(pipe("pbpaste"), header=TRUE)
header command indicates the variables have names.
births = read.table(file.choose(), header=TRUE)
attach(births) # Now R knows what the "birthweight" variable is
births$birthweight).
sep="\t" separated by tabs
na.strings="*" how to code missing values
strip.white=TRUE strip extra white space
iscamdotplot function to create a dotplot:
nrow(births) # Counts the number of observations
names(births) # Shows the variable names for your data
iscamdotplot(births$birthweight, # Use file name $ variable name
xlab="birth weight (g)", # Can add nicer horizontal axis label
main="graph of birthwt") # Can add title
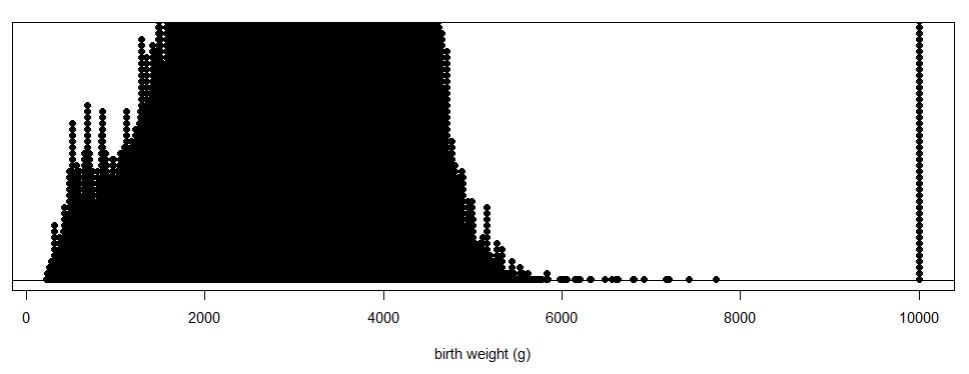

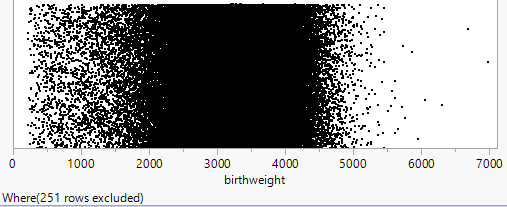
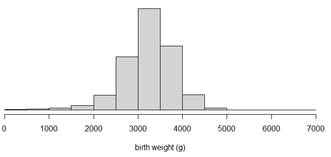
births2).
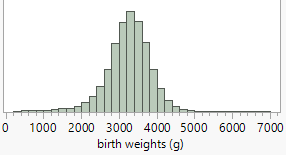
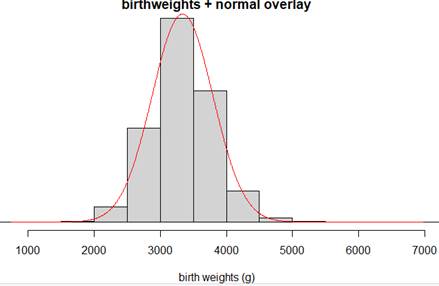
births2) and compare the information revealed by the dotplots and the histograms. Do you feel one display is more effective at displaying information about birth weights than the other? Explain.
births2 data based on whether or not the pregnancy lasted at least 37 weeks.
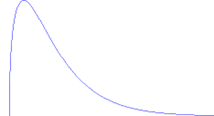
births3).
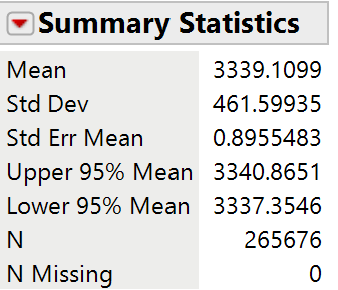
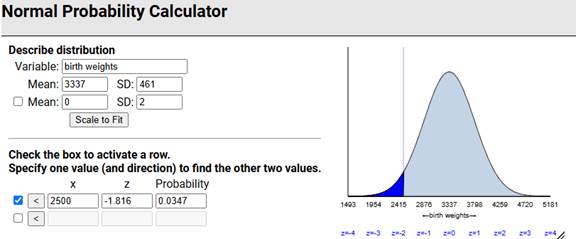
births3) that fall within 2 standard deviations of the mean.
within2sd = (births3$birthweight > mean(births3$birthweight) - 2*sd(births3$birthweight)) &
(births3$birthweight < mean(births3$birthweight) + 2*sd(births3$birthweight))
# Note: Make sure you copy this code with no line breaks
table(within2sd)/length(births3$birthweight)
births3 data: What percentage of the birth weights in this data set were at most 2500 grams? [Hint: Create a Boolean variable?] How does this compare to the prediction in the previous question? Does this surprise you? Explain.