Solution.
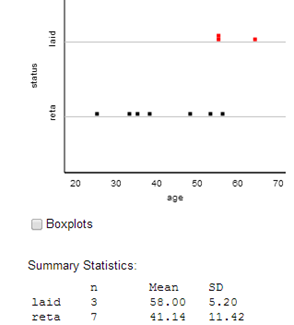
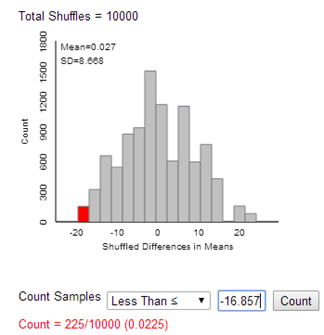
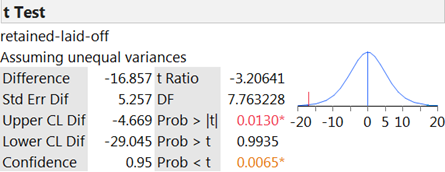
Let \(\mu_{fired} - \mu_{not fired}\) represent the difference in the average age of people that would be laid-off, in the long run (by the overall process), and the average age of the people who would be retained. (Don’t worry too much at this point about which stage of the firing process this analysis considers. Just keep in mind that we are trying to say something beyond the observed means. We believe there is some underlying difference in means and these data provide an estimate.)
\begin{gather*}
H_0: \mu_{fired} - \mu_{not fired} = 0 \text{ (no overall difference in the average ages of those getting fired and not)}\\
H_a: \mu_{fired} - \mu_{not fired} > 0 \text{ (those getting fired will tend to have higher ages than those not)}
\end{gather*}