Section 1.1 Investigation A: Distributions and Variability
These first three investigations give you a very brief introduction to some big ideas for the course. Some of you will have seen some of these ideas before and can use the investigations to refresh your memory. Some of the ideas may be new and you will see them again in later chapters. For now, try to focus on the bigger picture of analyzing data, evaluating models, and drawing appropriate conclusions.
Exercises 1.1.1 Investigation A: Hurricanes and Climate Change
One of the concerns with climate change is an increased number of tropical storms (including hurricanes and major hurricanes). In particular, in the "Atlantic Basin," scientists have tracked the number of "named storms" since 1851. According to the National Hurricane Center:
-
Tropical Storm: A tropical cyclone with maximum sustained winds of 39 to 73 mph (34 to 63 knots).
-
Hurricane: A tropical cyclone with maximum sustained winds of 74 mph (64 knots) or higher. In the western North Pacific, hurricanes are called typhoons; similar storms in the Indian Ocean and South Pacific Ocean are called cyclones.
-
Major Hurricane: A tropical cyclone with max sustained winds of 111 mph (96 knots) or higher.
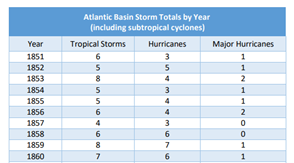
In 2020, scientists were alarmed because there were 14 recorded hurricanes, compared to 6 in 2019.
2. Evaluate the Evidence.
Does this convince you that climate change is leading to an increase in the number of hurricanes (in the Atlantic)? If so, explain why. If not, explain what additional information you would want to know.
Solution.
Just because one year saw a large increase doesn’t necessarily reflect an increasing trend. It’s also hard to know whether this is a "large" increase when we don’t have information on how much this value tends to vary from year to year. We can’t draw any causal conclusions because other things could have changed in that time frame. We also need to keep in mind that "number of hurricanes" is just one possible reflection of "climate change."
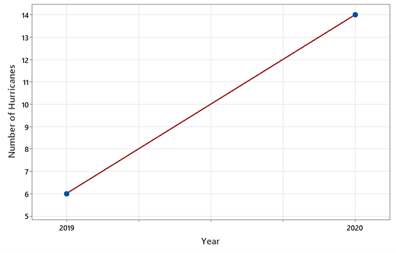
Below is a dotplot of the annual number of hurricanes from 1851 to 2024 \((n = 174)\text{.}\)
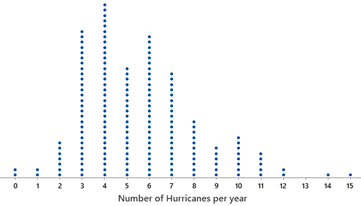
3. Interpret the Dotplot.
A year with 14 hurricanes is certainly close to record setting, but we expect there to be some variation from year to year. Below is a time plot of the number of hurricanes each year.
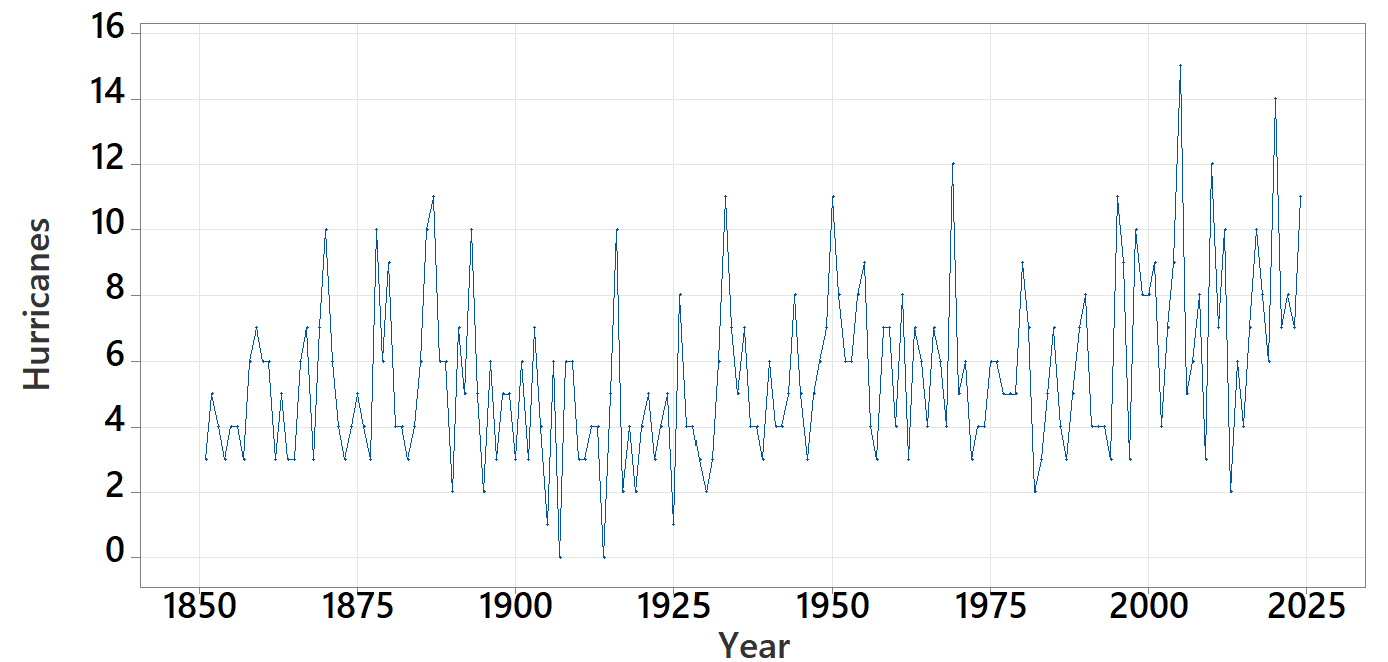
4. Compare Graph Types.
5. Assess Reported Mean.
The stormfax website reports the mean number of hurricanes between 1991-2020 to be 7. Does that appear consistent with the graph? Why do you think they chose that subset of years?
Solution.
Oftentimes a mean or average is reported, but with no measure of spread or variability. If all the years between 1991-2020 had between 6 and 8 hurricanes, we would react very differently to 14 hurricanes in one year than if all the years between 1991-2020 had between 2 and 15 hurricanes.
Terminology Detour: Standard Deviation.
The most common measure of the variability in a distribution of data is the standard deviation.
\begin{equation*}
s = \sqrt{\frac{\sum_{i=1}^n (y_i - \bar{y})^2}{n-1}}
\end{equation*}
We can roughly interpret the standard deviation as the average "deviation" of the data values in the distribution from the mean of the distribution. Another interpretation: If we were to predict 7 as the number of hurricanes in a year between 1991-2020, the standard deviation would approximate the average "prediction error" for those years.
Below is a dotplot of the data from 1991-2020 (\(n\) = 31).

6. Compare Subset to Full Dataset.
7. Estimate Standard Deviation.
8. Compare Standard Deviations.
Conjecture: How do you think the standard deviation from question 7 compares to the standard deviation of the full dataset? Explain your reasoning.
We will often use the standard deviation as a "ruler" to help us measure distances of observations from the mean of the distribution.
9. Standardize the Value.
Terminology Detour: Standardizing.
The general formula for standardizing an observation’s position in the distribution is:
\begin{equation*}
\frac{\text{observation value} - \text{mean of distribution}}{\text{standard deviation of distribution}}
\end{equation*}
We will often consider a value far from the mean of a distribution if it is more than two standard deviations away.
In this investigation, you have just touched on one piece of information related to climate change. In fact, scientists are less concerned about the number of storms but in the intensity of the storms and how warming of the surface ocean may be leading to more destructive storms. Looking at a single year in isolation or even a pair of years creates a very incomplete picture of trends over time, and while we expect some natural variation from year-to-year, the question to scientists is whether the overall trend being observed is larger than what we can reasonably attribute to natural variation.
Insight 1.1.1. Points to keep in mind.
-
It’s important to determine which variables are most relevant to the research question and whether you can collect the data you need to answer the question.
-
Simple graphs can be very informative, but you should also take care in considering the most meaningful variable representation of what you are studying even before you begin graphing.
-
It is imperative to consider variability and to think about possible sources of variation. Sometimes you may be able to explain and "control for" a source of variation. Often you will have to dig deeper into reasons for unusual observations and whether it is appropriate to remove them from the analysis.
-
The quality of your inferences will depend A LOT on the quality of the data that are collected. Not much can be learned from poorly or improperly collected data or data from a completely different time period.
Discussion.
When exploring a research question, one of the first steps is to define the variable involved (e.g., the number of hurricanes). This is an example of a quantitative variable, as opposed to a categorical variable like whether the storm has winds over 74 mph. Dotplots are good choices for visualizing a quantitative variable for a small dataset. When looking at a distribution of a single quantitative variable like this, we are often interested in four key features:
-
Center: What would you consider a "typical" value in the distribution?
-
Variability: How clustered together or consistent are the observations? Or are they far apart?
-
Shape: Are some values more common than others? Are the values symmetric about the center?
-
Are there any unusual observations that don’t follow the overall pattern? Are there any explanations for these values?
To summarize the center of the distribution, we often report the mean (the arithmetic average of all the numerical values in the data set) and/or the median (a middle value such that 50% of the data values are smaller and 50% are larger).
With most investigations we will also provide a follow-up practice problem or two for you to try on your own to assess your understanding of the material.
Subsection 1.1.2 Practice Problem A.A
Using the Descriptive Statistics applet (below or follow the link to open in a new tab) to complete this practice problem.
-
Press the Clear button
-
In the Paste data box, type
AtlanticStorms.txt. -
Press the Use Data button (twice).
-
Use the Quantitative Variable pull-down menu to select the Number of Hurricanes variable (Hurricanes).
Shape of Distributions.
The shape of a distribution is often classified as symmetric (mirror image on each side of the center) or skewed.
The skewness statistic measures the lack of asymmetry in a distribution (due values above the mean extend further than values below the mean on average) using a \((y_i-\bar{y})^3\) term. Positive values indicate a skewed right distribution, negative values indicate skewed left, and values near 0 indicate a symmetric distribution.
Checkpoint 1.1.2. Describe Shape.
Based on the graph, would you consider the "number of hurricanes" distribution to be symmetric, skewed to the right or skewed to the left? Check the Skewness statistic box, does the value agree with your judgement from the graph?
-
Skewed to the right
-
Skewed to the left
-
Symmetric
Mean and Median.
The mean, \(\bar{y}\text{,}\) is the average of all numerical values in the data set:
\begin{equation*}
\bar{y} = \frac{\sum_{i=1}^n y_i}{n}
\end{equation*}
The median is a value such that 50% of the data lies below and 50% of the data lies above that value: median position: \((n+1)/2\)
In the applet,
-
Check the box next to Guess for the Mean. Move the red line to where you think the mean of the distribution is.
-
Check the box next to Guess for the Median. Move the blue line to where you think the median of the distribution is.
-
Now check Actual for both.
Checkpoint 1.1.3. Explore the mean and median.
Checkpoint 1.1.4. Describe Variability.
In the applet, check the box for Guess for the standard deviation. Use your mouse to move one of the edges of the red rectangle to a distance that you think is representative of a "typical distance from the mean" (some values are closer, some are further). Then check the Actual box. How did you do?
Checkpoint 1.1.5. Compare Distributions.
How does the standard deviation of the full dataset compare to the 3.3 value for the years 1991-2020? Summarize what this tells us about the behavior of hurricanes.
You have attempted of activities on this page.
