Section1.2Investigation B: Randomness and Probability
In the previous investigation, you looked at historical data for the number of hurricanes that had occurred per year. As long as the “data generating process” doesn’t change, these data can give insight as to what will happen in the future. In this investigation, the goal is to explore a random process. We apologize in advance for the absurd but memorable process below.
Suppose that on one night at a certain hospital, four mothers give birth to four babies. As a very sick joke, the hospital staff decides to return babies to their mothers completely at random. Our goal is to look for the pattern of outcomes from this process, with regard to the issue of how many mothers get the correct baby. This enables us to investigate the underlying properties of this child-returning process, such as the probability that at least one mother receives her own baby.
Before we proceed, what do you think is more likely to happen: that no mothers get the correct baby, or that all four mothers get the correct baby? Write down your initial guess and explain your reasoning.
Because it is clearly not feasible to actually carry out this horrible child-returning process over and over again, we will instead simulate the random process to investigate what would happen in the long run. Suppose the four babies were named Murphy Miller, Wallis Williams, Bari Brown, and Shea Smith. Take four index cards and write the first name of each baby on a different card. Now take a sheet of paper and divide it into four regions, one for each mom. Next shuffle the index cards, face down, and randomly deal the babies back to the mothers. Flip the cards over and count the number of moms who received the correct baby.
The most common outcomes are typically 0 or 1 match. Having all 4 mothers receive the correct baby (4 matches) is very rare, as is having exactly 2 matches.
It is very unlikely that all four mothers received the correct baby in just 5 trials. More importantly, it is impossible for exactly three mothers to receive the correct baby - if three mothers get the right baby, the fourth mother must also get the right baby!
Press Randomize. Notice that the applet randomly returns babies to mothers and determines how many babies are returned to the correct home (by matching diaper colors). The applet also counts and graphs the resulting number of matches.
Click on the histogram bar representing the outcome of zero mothers receiving the correct baby. This shows you a "time plot" of the proportion of trials with 0 matches vs. the number of trials.
A random process generates observations according to a random mechanism, like a coin toss. Whereas we can’t predict each individual outcome with certainty, we do expect to see a long-run pattern to the results.
The probability of a random event occurring is the long-run proportion (or relative frequency) of times that the event would occur if the random process were repeated over and over under identical conditions.
You can approximate a probability by simulating (i.e., artificially recreating) the process many times. Simulation leads to an empirical estimate of the probability, which is the proportion of times that the event occurs in the simulated repetitions of the random process. Increasing the number of repetitions generally results in more accurate estimates of the long-run probabilities.
How does your empirical estimate from the simulation compare to your initial guess in question 1 (where you predicted whether zero matches or all four matches was more likely)?
In question 1, you predicted whether it was more likely that no mothers get the correct baby or that all four mothers get the correct baby. Compare that prediction to what you observed in the simulation.
Most people initially guess that having all four mothers get the correct baby is less likely than zero matches, and the simulation confirms this intuition. Zero matches occurs about 37.5% of the time, while all four matches occurs only about 4.2% of the time.
No, we would not expect to get exactly the same proportion. Due to random variability, the proportion will fluctuate somewhat from one set of 1000 trials to another. However, we would expect it to be close to the true probability (around 37.5%).
Look at the time plot in the applet that shows the running proportion of trials with 0 matches. What do you notice about the behavior of this proportion as the number of trials increases?
As the number of trials increases, the running proportion tends to stabilize and converge to the true probability (around 0.375). The proportion varies more with fewer trials but becomes more consistent with more trials.
One disadvantage to using simulation to estimate a probability like this is that everyone will potentially obtain a different estimate. Even with a very large number of trials, your result will still only be an estimate of the actual long-run probability. For this particular scenario however, we can determine exact theoretical probabilities.
First, let’s list all possible outcomes for returning four babies to their mothers at random. We can organize our work by letting 1234 represent the outcome where the first baby went to the first mother, the second baby to the second mother, the third baby to the third mother, and the fourth baby to the fourth mother. In this scenario, all four mothers get the correct baby. As another example, 1243 means that the first two mothers get the right baby, but the third and fourth mothers have their babies switched.
In this case, returning the babies to the mothers completely at random implies that the outcomes in our sample space are equally likely to occur (outcome probability = 1 / number of possible outcomes).
You could have determined the number of possible outcomes without having to list them first. For the first mother to receive a baby, she could receive any one of the four babies. Then there are three babies to choose from in giving a baby to the second mother. The third mother receives one of the two remaining babies and then the last baby goes to the fourth mother. Because the number of possibilities at one stage of this process does not depend on the outcome (which baby) of earlier stages, the total number of possibilities is the product \(4 \times 3 \times 2 \times 1 = 24\text{.}\) This is also known as \(4!\text{,}\) read "4 factorial." Because the above outcomes are equally likely, the probability of any one of the above outcomes occurring is \(1/24\text{.}\) Although these 24 outcomes are equally likely, we were more interested above in the probability of 0 matches, 1 match, etc.
A random variable maps each possible outcome of the random process (the sample space) to a numerical value. We can then talk about the probability distribution of the random variable. These random variables are usually denoted by capital roman letters, (e.g., \(X\text{,}\)\(Y\)). A random variable is discrete if you can list each individual value that can be observed for the random variable.
When the outcomes in the sample space are equally likely, the probability of any one of a set of outcomes (an event) occurring is the number of outcomes in that set divided by the total number of outcomes in the sample space.
Display the probability distribution table showing \(P(X = 0)\text{,}\)\(P(X = 1)\text{,}\)\(P(X = 2)\text{,}\)\(P(X = 3)\text{,}\) and \(P(X = 4)\text{.}\)
The simulation results should be fairly close to the exact probabilities, especially with 1000 or more trials. Small differences are expected due to random variability in the simulation.
Addition rule for disjoint events: The probability of at least one of several events is the sum of the probabilities of those events as long as there are no outcomes in common across the events (i.e., the events are mutually exclusive or disjoint).
We can also consider the expected value of the number of matches, which is interpreted as the long-run average value of the random variable. For a discrete random variable, \(X\text{,}\) we can calculate the expected value of the random variable \(X\text{,}\) denoted \(E(X)\text{,}\) by employing the idea of a weighted average of the different possible values of the random variable, but now the "weights" will be given by the probabilities of those values:
The expected value of 1 means that in the long run, on average, 1 mother will receive the correct baby per trial. This does NOT mean that in any single trial we expect exactly 1 match - in fact, we could get 0, 1, 2, or 4 matches. The expected value is the average across many trials.
But from the results we saw above, each term \((\#)/1000\) converges to the probability of that outcome as we increase the number of repetitions, giving us the above formula for \(E(X)\text{.}\) So we will interpret the expected value as the long-run mean of the outcomes.
Another property of a random variable is its variance. This measures how variable the values of the random variable will be. For a discrete random variable, \(X\text{,}\) we can again use a type of weighted average, based on the probabilities of each value and the squared distances between the possible values of the random variable and the expected value.
\(SD(X) = \sqrt{1} = 1\text{.}\) The standard deviation of 1 means that the number of matches typically varies by about 1 from the expected value of 1 match.
We will interpret this standard deviation similarly to how we did in Investigation A: how far the outcomes tend to be from the expected value. Here we are talking in terms of the probability model; in Investigation A we were talking in terms of the historical data.
Go back to the Random Babies applet and run a large number of simulations (at least 10,000). Calculate the mean and standard deviation of your simulated results. How do these compare to the theoretical expected value and standard deviation you calculated?
With a large number of simulations (10,000+), the mean should be very close to 1.0 and the standard deviation should be very close to 1.0, matching the theoretical values.
This approach of looking at the analysis using both simulation and exact approaches will be a theme in this course. We will also consider some approximate mathematical models as well. You should consider these multiple approaches as a way to assess the appropriateness of each method. You should also be aware of situations where one method may be preferable to another and why.
Calculate the (exact) probability that all 8 mothers receive the correct baby. [Hint: First determine how many possible outcomes there are for returning 8 babies to their mothers.]
Using the Random Babies applet, approximate the probability that at least one of the 8 mothers receives the correct baby. How does your approximation compare to the probability of this event with 4 mothers?
Using the Random Babies applet, approximate the expected value for the number of the eight mothers receiving the correct baby. How does your approximation compare to the situation with 4 mothers?
An American Roulette wheel consists of 18 black slots, 18 red slots, and 2 green slots. A ball is rolled while the wheel is spun and players can bet on which slot or type of slot the ball will end up in.
A common bet is color. If someone bets $1 on red, and the ball lands in any of the 18 red slots, the player wins $2 (a net profit of $1). What is the probability they will win their bet on red?
Checkpoint1.2.11.Probability of Winning Number Bet.
Another common bet is a number. If the ball lands on the chosen number, the player makes a profit of $35. What is the probability someone wins if they bet on a number?
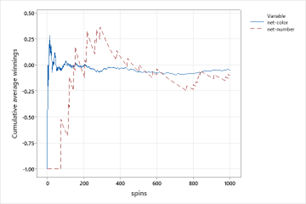
Below are two graphs showing the average net winnings over 1000 simulated plays of a color bet and of a number bet. [Hint: What happened on the first 50 or so number bets?] Explain how you think the expected value (long-run average winnings) of each bet compares. Do they have the same sign?
Look at where the graphs appear to be stabilizing as the number of plays increases. What does the long-run average appear to be approaching for each bet?