Section 5.6 Investigation 1.15: Counting Concussions
In this investigation, you will learn about another probability distribution that allows you to calculate exact p-values when sampling from a population (rather than from a random process).
Exercises 5.6.1 The Study
Concussions, particularly among high school and collegiate athletes, have been given increased attention in recent years. A 2017 national Youth Risk Behavior Survey found about 15.1% of U.S. high school students reported having at least one concussion in the previous year. Prevalence was higher among those who played on a sports team.
A student project group was interested in the probability of concussion among the male soccer and football players at their university. They sent a survey to the team rosters and found that 12 of the 33 respondents reported at least one concussion in the previous two years (2017–2019). The anonymous survey was emailed to all 110 players, and included a list of injuries asking "yes or no questions about various injuries, in order to distract the athletes of the true purpose of our survey." Based on these data, is there evidence that the proportion of all 110 male soccer and football players at this university who had at least one concussion in the last 2 years is larger than 0.15?
2. Identify response variable.
Identify the response variable in this study. How are you defining a "success"?
3. Variable type.
Is the response variable quantitative or categorical?
-
Quantitative
-
Categorical
4. Identify sample and population.
Identify the sample, the population, and the sampling frame used in this study.
Definition: Non-sampling Errors.
Non-sampling errors can occur even after we have a randomly selected sample. They are not associated with the sampling process, but rather with sources of bias that can arise after the sample has been selected.
Sources of non-sampling errors in surveys include biased, dishonest, or inaccurate responses by respondents due to leading word choice in survey questions, sensitive questions, faulty memory, the order in which questions appear, a leading tone, and the appearance of the interviewer.
5. Identify precautions.
Identify some precautions taken by these students to avoid nonsampling errors.
6. Examine sample data.
7. Assess representativeness.
Do you think it is reasonable to consider this sample as representative of all varsity team football and soccer players at this school? Explain why or why not.
We can still ask: "If the population proportion was 0.15, would it be unlikely for a random sample from this population to produce such a large sample proportion?" This question should sound familiar, but now we need to consider that the sample did not come from a large population and this can impact our estimate of the amount of random sampling variation.
8. Calculate probability for one athlete.
9. Calculate conditional probabilities.
Now consider randomly selecting a second athlete from this population:
Hint.
If the first athlete had a concussion, what is the probability the second athlete did as well?
If the first athlete did not have a concussion, what is the probability the second athlete did?
You should find your answers in Question 9 are not quite the same. This illustrates a violation of the independence assumption of our binomial model. However, if the population is large compared to the size of the sample, then the conditional probabilities are almost equal, and we can approximate with a binomial distribution. But when the population is not large, we need to take that lack of independence into account.
Key Result: Sampling Without Replacement.
When sampling without replacement from a finite population that is not more than 20 times the size of the sample, the "trials" are no longer independent.
The consequence is that we should not use the binomial distribution to calculate \(P(X \geq 12)\text{.}\) Instead of a calculation like \(\binom{33}{12}(0.155)^{12}(1-0.155)^{21}\text{,}\) we would need a calculation like
\begin{equation*}
(17/110)(16/109) + \ldots + (17/110)(17/109) \ldots
\end{equation*}
for all the possible sequences of outcomes. Turns out there is a different probability distribution we can use called the hypergeometric distribution.
To calculate hypergeometric probabilities, we need to consider another probability rule.
When outcomes are equally likely, then the probability of an event equals the number of ways for the event to happen divided by the total number of possible outcomes.
For example, there are 268 words in the Gettysburg Address, 125 contain the letter e (about 46.6%) and 143 do not. Using counting rules, there are \(\binom{268}{5} = 11,096,761,368\) different samples of 5 words that we could select from the Gettysburg Address. But if we want to select one e-word and four non-e-words, there are \(\binom{125}{1} \times \binom{143}{4} = 2,087,710,625\) such samples. Thus, if \(X\) = number of e-words in a sample of 5 words, we find \(P(\text{one e-word}) = P(X = 1) = 2,087,710,625 / 11,096,761,368 \approx 0.188\text{.}\)
Probability Detour — Hypergeometric Random Variables.
To be a Hypergeometric random variable, a random process must have the following properties:
The main distinction between a hypergeometric random variable and a binomial random variable is the trials are no longer independent. The probability of drawing a success for the first object is \(M/N\text{.}\) But if we do draw a success, then the probability of success for the second object is \((M - 1)/(N - 1)\text{.}\) If we replaced the item, then we would be back to a binomial process.
In general, the probability of obtaining \(k\) successes from a population with \(M\) successes and \(N - M\) failures is
\begin{equation*}
P(X = k) = \frac{\binom{M}{k} \times \binom{N-M}{n-k}}{\binom{N}{n}}
\end{equation*}
where \(\binom{a}{b} = \frac{a!}{b!(a-b)!}\)
The expected value of the hypergeometric random variable is \(E(X) = (M/N) \times n\) and the standard deviation is
\begin{equation*}
SD(X) = \sqrt{n \times (M/N) \times ((N-M)/N) \times ((N-n)/(N-1))}
\end{equation*}
(Compare these to a binomial with \(\pi = M/N\text{.}\))
10. Technology Detour — Calculating Hypergeometric Probabilities.
Continuing to suppose 17 of the 110 athletes had a concussion, use technology to find the probability that a random sample of 33 would have 12 or more successes.
Hint 1. R Instructions
The
iscamhyperprob function takes the following inputs:
-
k, the observed value of interest (or the difference in conditional proportions, assumed if value is less than one, including negative) -
total, the total number of observations in the population -
succ, the overall number of successes in the population -
n, the sample size -
lower.tail, a Boolean which is TRUE or FALSE
For example:
Hint 2. JMP Instructions
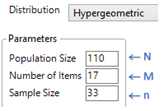
Using the Distribution Calculator in the ISCAM Journal File:
-
Select Hypergeometric from the Distribution menu.
-
Specify the Population Size, the number of successes in the population (Number of items) and the sample size.
-
Choose the tail probability and specify the number of interest (e.g., 12)


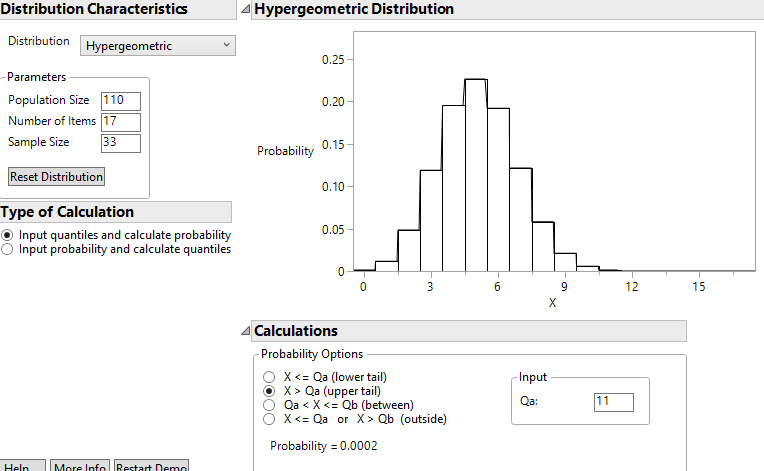
11. Report p-value.
12. Interpret the probability.
Write a one-sentence interpretation of the probability you calculated.
13. Generalization to larger population.
What does the p-value in Question 11 tell you about the proportion of all U.S. collegiate football and soccer players with a concussion?
Solution.
Question 11
This sample was not randomly selected from the population of all U.S. collegiate football and soccer players, so this sample really tells us nothing about the likelihood of a concussion among the larger population.
Discussion.
The hypergeometric distribution is able to tell us that if we listed all possible samples of 33 players from this population, how many would be at least as extreme as the observed sample. In many sampling situations, our population size is large enough that the binomial distribution gives a very reasonable approximation to the exact p-value. For this reason, the binomial p-value is much more commonly used than the hypergeometric p-value.
Probability Detour — Binomial Approximation to Hypergeometric Distribution.
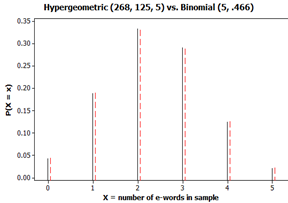
These probability calculations work out to be very similar! This happens when the finite population we are sampling from is large compared to our sample size (e.g., \(N > 20 \times n\)). This means we can continue to use the binomial distribution to determine such probabilities and the expected number of successes \(5(0.466) \approx 2.33\) with \(SD(X) \approx 1.115\) successes. And when the sample size is large relative to the probability of success, we can approximate the binomial with the normal distribution.
Study Conclusions.
Only about 0.02% of random samples of 33 players from a population of 110 players with 17 successes would have 12 or more successes in the sample by random chance (random sampling) alone. This survey would give us very strong evidence that the proportion of players with at least one concussion in this population was larger than 0.155, but there are many problems with this conclusion. This was not a random sample from the population of all athletes at this school (voluntary response, no follow-up) and is likely susceptible to sampling bias. Perhaps athletes who recently had a concussion would be more motivated to voluntarily complete the survey. Because of these issues with the sampling method, the p-value that we calculated is really not all that appropriate or meaningful. We should also consider that the 15% value cited by the YRBS came from one year of data vs. during the previous two years. Nevertheless, getting accurate reports on concussion rates is a challenging but critical task in helping to prevent possibly debilitating injuries, especially in high contact high school and college sports.
Subsection 5.6.2 Practice Problem 1.15A
Checkpoint 5.6.1. First-year student voting preferences.
A 2004 student project asked 30 students from the 705 first-year students at their school whether they planned to vote for Bush or Kerry in the upcoming election. For half of the surveys, Kerry was listed first and for half of the surveys Bush was listed first. (Why?) They found 22 planned to vote for Kerry. Does this convince you that more than 2/3 of first-year students at this school planned to vote for Kerry?
Subsection 5.6.3 Practice Problem 1.15B
Checkpoint 5.6.2. GSS non-sampling errors.
Recall the GSS survey in Practice Problem 1.14. Identify potential non-sampling errors in such a study. What are some steps the GSS has taken/could take to avoid non-sampling errors?
You have attempted of activities on this page.
