Let
\(\mu_A\) = population mean walking distance for African elephants and
\(\mu_{As}\) = population mean walking distance for Asian elephants.
\(H_0: \mu_A - \mu_{As} = 0\) (no difference),
\(H_a: \mu_A - \mu_{As} \neq 0\) (there is a difference). Test statistic:
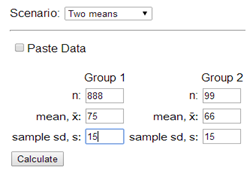
\(t = 0.13\text{,}\) p-value = 0.897. The standardized statistic of 0.13 indicates the observed difference is only 0.13 standard errors from 0, which is very small. The p-value of 0.897 means if there were no difference in population mean walking distances, we would observe a difference at least as extreme as ours in about 90% of random samples. We fail to reject the null hypothesis; there is insufficient evidence of a difference in mean walking distances.