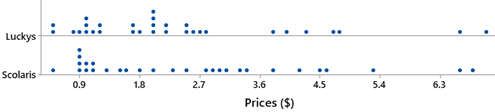
An important first step in data analysis is always to explore your data! With these data, we found some unusual observations and upon further investigation realized that one data value had been recorded in error (e.g., milk). In this case, we would be justified in removing this observation from the data file (we did not have any justification for removing the other outliers). After cleaning the data, we found that the price differences were slightly skewed to the left with a few outliers (flour, toothpaste, and frozen yogurt). The average price difference (Lucky’s
\(-\) Scolari’s) was
\(-\$0.118\text{,}\) with a standard deviation of
\(\$0.359\text{.}\) The median price difference was
\(\$0\text{.}\) So though the sample did not show a strong tendency for one store to have lower prices, the sample mean difference was in the conjectured direction. A one-sided paired
t-test found that the mean price difference between these two stores was significantly less than 0 (
t-value =
\(-1.74\text{,}\) p-value = 0.046) at the 10% level of significance, and even (barely) at the 5% level. A 95% confidence interval contained zero (as the two-sided p-value would be larger than 0.05). A 90% confidence interval for the mean price difference was (
\(-0.234\text{,}\) \(-0.003\)). We can be 90% confident that, on average, items at Scolari’s cost between 0.3 cents and 23 cents more than items at Lucky’s. This seems like a small savings but could become practically significant for a very large shopping trip. (Note, the average savings is not the same as the savings we would expect on an individual item.) In fact, we are 90% confident that an individual item will be anywhere from 74 cents more expensive at Scolari’s to 50 cents more expensive at Lucky’s. We feel comfortable generalizing these conclusions to the population of all products common to the two stores because the data were randomly selected using a probability method (systematic random sampling).