In this first investigation you will be introduced to a basic statistical investigation as well as some ideas and terminology that you will utilize throughout the course. You will combine ideas from the preliminary investigations: examining distributions of data and simulating models of random processes to help judge how unusual an observation would be for a particular probability model
In a study reported in the November 2007 issue of Nature, researchers investigated whether infants take into account an individual’s actions towards others in evaluating that individual as appealing or aversive, perhaps laying the foundation for social interaction (Hamlin, Wynn, and Bloom, 2007). In other words, do children who aren’t even yet talking still form impressions as to someone’s friendliness based on their actions?
In one component of the study, sixteen 10-month-old infants were shown a “climber” character (a piece of wood with “googly” eyes glued onto it) that could not make it up a hill in two tries.
Then the infants were shown two scenarios for the climber’s next try, one where the climber was pushed to the top of the hill by another character (the “helper” toy) and one where the climber was pushed back down the hill by another character (the “hinderer” toy). The infant was alternately shown these two scenarios several times.
A sample is a collection of observed outcomes generated by repeated realizations of a random process. The set of observations should reflect the typical behavior, and the variability inherent in that process. A study’s sample size is the number of outcomes observed.
Opinions will vary, but if we consider the infants as interchangeable (no differences between them) and the infants’ choices were all measured separately, than this modeling assumption seems appropriate. In particular, we need to be willing to model each infant as having the same probability of picking the helper toy.
Why is it important that the researchers varied the colors and shapes of the wooden characters and even on which side the toys were presented to the infants?
The measurements we are taking define the variable. We classify the type of variable as categorical (assigning each observational unit to a category) or quantitative (assigning each observational unit a numerical measurement). A special type of categorical variable is a binary variable, which has just two possible outcomes (often labeled “success” and “failure”).
A research question often looks for patterns in a variable or compares a variable across different groups or looks for a relationship between variables.
The research question is whether infants in general (assuming identical infants from a random process) are more likely to pick the helper toy than the hinderer toy in the long run.
To summarize the distribution of a categorical variable, we can simply count how many are in each category and make a bar graph to display the results, one bar for each outcome, with heights representing the number of observations in each category, separating the bars to indicate distinct categories.
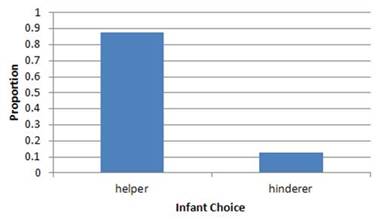
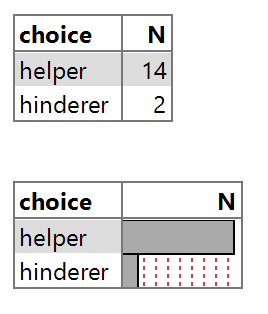
The “raw data” can be found on the course webpage as a txt file (InfantData.txt). How many do you see of each possible outcome? Sketch the bar graph. Give your graph an “active title,” a concise sentence stating the main message/key takeaways from the graph. What is your title?
Use technology (R or JMP) to create a bar graph of these data. Choose one set of instructions below by clicking on a hint below. See also Using Technology with This Book.
Choose File > New > Data table. Open the InfantData.txt (raw data) link and select all the observations and the variable name (e.g., ctrl-A) and copy into the clipboard (e.g., ctrl-C).
Clearly a majority/more than half of the infants chose the helper toy in this sample of 16 infants. But does that convince us that infants in general are more likely to pick the helper toy in the long run? In other words, what is the probability that an infant will choose the helper toy?
Model assumption: Note we are assuming each infant has the same probability of picking the helper toy, we just don’t know the value of that probability.
Is it possible that in the long run infants just choose equally between the two toys (e.g., the probability an infant will choose the helper toy is 0.5) and we just happened to see more than half choose the helper toy in our sample?
Not quite. The researchers varied the colors, shapes, and positions of the toys to balance out these factors, so color preference is not a plausible explanation.
No
Correct! We are not considering color, shape, or position as the explanation because these factors were balanced in the design of the study.
Infants choose equally between the two toys in the long run and we happened to get “lucky” and had an unusual sample where most of the infants in our sample picking the helper toy.
So for the two possibilities we are still considering, how might you choose between them? In particular, how might you convince someone whether or not option (2) is plausible based on this study?
Our analysis approach is going to be to assume the second explanation is true (similar to how in a legal trial we assume a defendant is innocent), and then see whether our data are consistent or inconsistent with that assumption. To do this, we need to investigate the values we expect to see for the number choosing the helper toy when 16 infants are equally choosing between the two toys. As you saw with the Random Babies (Investigation B), we can simulate the outcomes of a random process to help us determine which outcomes are more or less likely to occur.
We could toss a coin for each infant, letting heads represent choosing the helper toy and tails represent choosing the hinderer toy. This makes the two choices equally likely on each toss. Then use 16 coins or toss one coin 16 times to represent the 16 infants. (We are assuming these are equivalent, that the observational units are identical.) These results will help us assess the variability in the outcomes of 16 infants "just by chance." This will help us decide whether 14 is a typical outcome or an unusual outcome when we know for a fact that the "infants" choose equally (in the long run) between the two toys.
For a 50-50 simulation model, we can flip a fair coin. We can arbitrarily define “heads” to be choosing the helper toy and “tails” to be choosing the hinderer toy. We will repeat the random process 16 times to represent the 16 infants, and we will count how many times we flip heads, representing an infant choosing the helper toy. The chart below shows this mapping of the real world, which we saw one instance of, and the simulation model, which we can easily repeat many times. Keep in mind that in the simulation model, we know the probability of heads is 0.50.
Flip a coin 16 times, representing the 16 infants in the study (one repetition of this random process). Tally the results below and count how many of the 16 chose the helper toy:
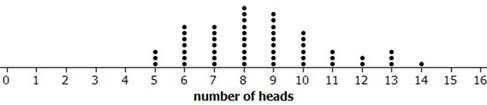
Combine your simulation results for each repetition with your classmates’ on the scale below. Create a dotplot by placing a dot above the numerical result found by each person’s set of 16 tosses.
Did everyone get the same number of heads every time? What is an average or typical number of heads in a set of 16 tosses? Is this what you expected? Explain.
We really need to simulate this hypothetical random selection process hundreds, preferably thousands of times. This would be very tedious and time-consuming with coins, so let’s turn to technology.
Use the One Proportion Inference applet to simulate these 16 infants making this helper/hinderer choice, still assuming that infants have no real preference and so are equally likely to choose either toy.
Report the number of heads (i.e., the number of infants who choose the helper toy) for this “could have been” (under the assumption of no preference) outcome.
In the applet, uncheck the Show animation box and press Draw Samples four more times, each time recording the number of the 16 infants who choose the helper toy.
Now change the Number of repetitions to 1995 and press Draw Samples, to produce a total of 2,000 repetitions of this random process of tossing a coin 16 times.
Correct! The variable "number of heads" is quantitative because it represents a numerical count that can be measured and has meaningful numerical values.
Categorical
Not quite. The number of heads is a count (0, 1, 2, ..., 16), which makes it quantitative rather than categorical. Categorical variables assign observations to categories, not numerical values.
Now that we have a better picture of the long-run behavior of this process, discuss whether you would consider option 2 before Question 12: “Infants choose equally between the two toys in the long run and we happened to get ’lucky’ and find most of the infants in our sample picking the helper toy” to be a plausible conclusion for this study. Explain your reasoning as if to a skeptic.
Look at how often 14 or more heads occurred in your 2,000 simulated repetitions. Is this common or rare? What does this tell you about the plausibility of the "no preference" assumption?
Because it is very unlikely for us to have seen results at least as extreme as what we observed (14 successes) under the assumption of 50-50 chance, we have evidence against this claim and instead in favor of the claim that there is something other than random chance at play in this sample.
Returning to our legal trial analogy, if you decide that the observed “data” is unlikely to occur by chance alone, you are going to “reject” the assumption of “innocence” (and say we have evidence the defendant is guilty). If you decide the data/evidence is not unusual by chance alone, then you “fail to reject” that assumption (and we say we don’t have evidence the defendant is guilty — we aren’t proving the defendant innocent, just that the evidence is not inconsistent with that assumption, “not guilty”).
So based on these simulation results, we would say the data (14 helper choices out of 16 trials) is unusual under the assumption that infants genuinely have no preference and are choosing blindly when presenting the toys. This evidence convinces us that “There is something to the theory that infants are genuinely more likely to pick the helper toy (for some reason)” is the more believable explanation for why so many of the infants in this study picked the helper toy over the hinderer toy. We haven’t proven this is true, but based on the strong majority these researchers saw, even for this small sample size of 16, we would consider the evidence convincing (“beyond a reasonable doubt”) that, in the long run, the probability of choosing the helper toy in this random process is greater than 0.5. Because the researchers controlled for other possible explanations for the observed preference results like color and handedness, we will conclude that there is convincing evidence that infants really do have a genuine preference for the helper toy over the hindering toy.
In a study of “social evaluation,” researchers explored whether pre-verbal infants have a preference for a “helping” toy over a “hindering” toy. Treating the 16 infants as identical observations from a random process with equal probability of success/failure, we find that getting 14 infants choosing the helper toy is not consistent with the types of values we expect to see when we have “infants” choosing equally between the two toys. This means that the researchers’ data provide strong statistical evidence to reject this “no preference” model and conclude that the infants’ choices are actually governed by a process where there is a genuine preference for the helper toy (or at least that it’s more complicated than each infant flipping a coin to decide). Of course, this conclusion depends on the assumption of “identical infants” and that these 16 infants’ choices are representative of the larger process of viewing the videos and selecting a toy. Also keep in mind that not all infants had a clear preference for either object.
In a second experiment, the same events were repeated but the object climbing the hill no longer had the googly eyes attached. The researchers wanted to see whether the preference was made based on a social evaluation more than a perceptual preference. Suppose 8 of 12 (different) infants chose the push-up toy.
Checkpoint3.1.23.Determine Sample Size for Simulation.
If you were to use a coin to carry out a simulation analysis to evaluate these results: how many times would you flip the coin for one repetition — 6, 8, 10, 12, 16, or 1000?
Not quite. Think about how many infants were in this experiment.
8
Close, but this is the number who chose the push-up toy, not the total number of infants.
10
Not quite. Check the problem statement for the total number of infants in the experiment.
12
Correct! You need to flip the coin 12 times to represent the 12 different infants in this experiment, just like we flipped 16 times to represent the 16 infants in the original study.
16
Not quite. That was the sample size in the original study, but this experiment has a different number of infants.
1000
Not quite. 1000 would be the number of repetitions we might do, not the number of coin flips per repetition.
Use the One Proportion Inference applet to decide whether it is plausible that when the googly eyes are removed infants do not have a genuine preference between the two toys. What do you conclude?
In 2019, the home team won 54 of the first 88 games of the Premier Soccer League season. Consider these games as a sample from a random process (all games that could have occurred in first 3 months).
Could we use a coin tossing simulation to model this random process? What would each coin toss represent? What are we assuming about the process? How many times would we toss the coin for one repetition? Define what is meant by “probability of success” in this context.
Use the One Proportion Inference applet to decide whether these data provide convincing statistical evidence that the home team is more likely than the visiting team to win in the long run. Justify your conclusion.
Checkpoint3.1.27.Test Home Advantage Without Fans.
At the beginning of the 2020 season, fans were not allowed at the games due to the Coronavirus pandemic. For the first three months of this season, the home team won 40 of 87 matches. Decide whether these data provide convincing statistical evidence that the home team is more likely than the visiting team to win when no fans are present. Justify your conclusion.