Poloneicki, Sismanidis, Bland, and Jones (2004) reported that in September 2000 heart transplantation at St. George’s Hospital in London was suspended because of concern that more patients were dying than previously. Newspapers reported that the 80% mortality rate in the last 10 cases was of particular concern because it was over five times the national average. The variable measured was whether or not the patient died within 30 days of the transplant. Although there was not an officially reported national mortality rate (probability of death within 30 days for patients undergoing this procedure), the researchers determined that 15% was a reasonable benchmark for comparison.
The 10 most recent heart transplantation surgeries at St. George’s Hospital (or more generally, heart transplantation surgeries at this hospital, across all the patients)
We need to consider which outcome we will consider "success" and which we will consider "failure." The choice is often arbitrary, though sometimes we may want to focus on the more unusual outcome as success. In fact, in many epidemiology studies, "death" is typically the outcome of interest or "success."
If there is nothing unusual about the mortality rate for heart transplantations at this hospital (compared to other U.K. hospitals), what does this imply about the value of the probability of "success"?
If the patients at this hospital are indeed dying at a higher rate than the benchmark rate, what does this imply about the value of the probability of "success"?
Translate your answers to the previous questions to null and alternative hypothesis statements. Keep in mind, the null hypothesis claims the observed result is "just by chance," whereas the alternative hypothesis translates the research conjecture.
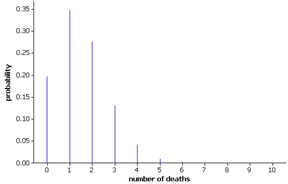
Of the hospital’s ten most recent transplantations at the time of the study, there had been eight deaths within the first 30 days following surgery. Is this sample result in the direction suspected by the researchers? Explain.
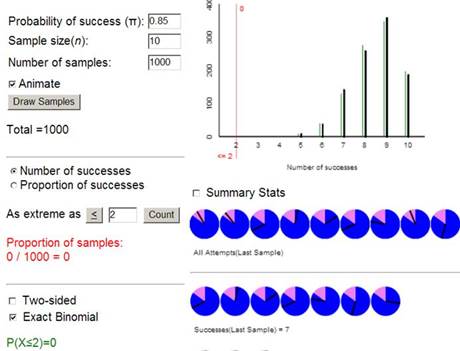
You could use the One Proportion Inference applet to use simulation or the binomial distribution to find the p-value. Many statistical software packages will carry out a "Binomial test" directly.
Use R or JMP to find and report the p-value for the Heart Transplant study (8 deaths in 10 trials with hypothesized probability 0.15). Choose one set of instructions below by clicking on a hint. Report the p-value you find.
You should see the p-value in the output as well as a graph of the binomial distribution with the upper tail shaded. Modify the code for the heart transplant study, in particular, what are you setting the hypothesis value to?
JMP assumes "success" to be the first category alphabetically unless you specify otherwise with Cols > Column Info > Column Properties > Value Ordering.
This is the probability of getting 8 or more "successes" out of 10 observations from a random process where the long-run probability of success equals 0.15.
We have very strong evidence in favor of \(\pi > 0.15\) (\(H_a\)). We don’t think the higher mortality rate observed in these 10 cases happened just by chance.
Describe how the hypotheses would change and how the calculation of the binomial p-value would change. Then go ahead and calculate and interpret the exact binomial p-value with this set-up. How does its value compare to your answer in the previous question? How (if at all) does your conclusion change?
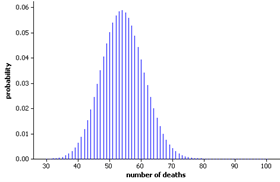
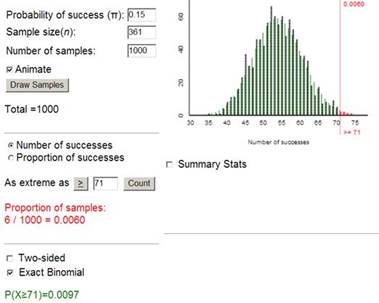
Following up on the suspicion that the sample of size 10 aroused, these researchers proceeded to gather data on the previous 361 patients who received a heart transplant at this hospital dating back to 1986. They found 71 deaths within 30 days among heart transplantations.
Is the probability you found convincing evidence to consider the sample result surprising if the mortality rate at this hospital matched the national rate? Explain.
Is the evidence against the null hypothesis stronger or weaker than the earlier analysis based on 10 deaths? Explain how you are deciding and why the strength of evidence has changed in this manner.
The following graphs display the two theoretical probability distributions (for sample sizes \(n = 10\) and \(n = 361\)), both assuming the null hypothesis (\(\pi = 0.15\)) is true. These graphs show just how far the observed values (8 and 71) are from the expected value of the number of deaths (0.15 × 10 = 1.5 and 0.15 × 361 = 54.15) in each case. You should also note that the shape, center, and variability of the probability distribution for number of successes are all affected by the sample size \(n\text{.}\)
Keep in mind that of interest to us is the observed statistic’s relative location in the null distribution. Thus, we are most interested in how variable the possible outcomes are from the "expected" outcome. The center of the distribution isn’t all that interesting to us in answering the research question because we determine what the center of the distribution will be by how we specify the null hypothesis. Even the shape isn’t all that interesting on its own in answering our research question.
For first data set: \((8 - 1.5)/\sqrt{10 × 0.15 × 0.85} = 6.5/1.13 = 5.75\) (this shows us that the evidence is a fair bit stronger with the first data set)
Yes, this provides strong evidence against the null hypothesis. A result more than 2 standard deviations from the expected value is generally considered unusual, and 2.49 SD is quite far from the mean.
Opinions will vary. The larger sample size is more likely to give us more precise results but some based on very old data which may no longer be representative of the current process.
A sample mortality rate of 80% is indeed quite surprising, even with a sample size as small as 10, if the actual probability of death were 0.15. The (exact) p-value is 0.0000087, and the observed statistic is 5.76 standard deviations above the expected value, providing extremely strong evidence that the actual probability of death at this hospital is higher than the national benchmark of 0.15 (fewer than 1 in 100,000 sets of 10 operations would "randomly" have 8 or more deaths if \(\pi = 0.15\)). However, we must be cautious about doing this type of "data snooping," where we allowed a seemingly unusual observation to motivate our suspicion and then use the same data to support our suspicion. Once the initial suspicion has formed, we should collect new data on which to test the suspicion. The actual investigation examined all previous heart transplantations at this hospital over the previous 14 years. In this broader study, the p-value is 0.0097 and the observed number of successes is 2.48 standard deviations above the expected number, still providing very strong evidence against the null hypothesis. That is, there is strong evidence that this hospital’s probability of mortality was higher than the 15% national benchmark. We must, however, be cautious because our study has not identified what factors could be leading to the higher rate. Perhaps this hospital tends to see sicker patients to begin with. The researchers actually performed a more sophisticated analysis that incorporated information about the risk factors of all the operations at this hospital and reached similar conclusions.
In April 2014, the city of Flint Michigan switched its water supply to the Flint River in an effort to save money. The U.S. Environmental Protection Agency (EPA)’s Lead and Copper Rule states that if lead concentrations exceed an action level of 15 parts per billion (ppb) in more than 10% of homes sampled, then actions must be undertaken to control corrosion, and the public must be informed. In the initial sample of 71 homes, 8 tested above 15 ppb.
Suppose our variable is "was the lead concentration level above 15 ppb?". Is it reasonable to model this as a binomial process? Justify your response for each condition. Be sure to explain how you are defining success and any assumptions you are making about the process.
After dropping two "suspicious" observations, 6 of the 69 remaining observations were above 15 ppb. Report the binomial p-value for your hypotheses. Is the second p-value larger or smaller than the first?
Reconsider the wolf (Yukon) who correctly understood a communicative cue in 7 of 8 attempts. Let \(\pi\) represent the probability of Yukon identifying the correct container with a communicative cue.
If the alternative hypothesis is \(H_a: \pi > 0.50\text{,}\) what is the p-value? Based on this p-value, state an appropriate conclusion in terms of the alternative hypothesis.
If the alternative hypothesis is \(H_a: \pi < 0.50\text{,}\) what is the p-value? Based on this p-value, state an appropriate conclusion in terms of the alternative hypothesis.
One of the first times the U.S. Supreme Court considered statistical significance in an employment discrimination case was in Hazelwood School District vs. United States (1977). The U.S. government sued the City of Hazelwood, a suburb of St. Louis, MO, on the grounds that it discriminated against African Americans in its hiring of school teachers. The evidence introduced noted that of the 405 teachers hired in 1972 and 1973 (the years following the passage of the Civil Rights Act), only 15 had been African-American. By comparison, according to 1970 census figures, of the almost 20,000 elementary and secondary teachers employed in the St. Louis area, 15.4% were African American. We want to decide whether the data on these 405 teachers is convincing evidence that the Hazelwood hiring process had a probability of a new hire being African American that was less than 0.154.
What is the expected number of African-American hires in a sample of 405 teachers if the probability of a new hire being African American equals 0.154?
Using the binomial distribution, how many standard deviations is 15 from the expected number of new hires that are African American when the null hypothesis is true?
The St. Louis City School District had recently followed a policy attempting to maintain a 50% African-American teaching staff. If you exclude the St. Louis City School District, then the proportion of eligible teachers in the St. Louis area that were African-American was 0.057. What is the new expected number of hires? What conclusions would you draw?