Section13.1Investigation 3.1: Teen Hearing Loss (cont.)
Exercises13.1.1The Study
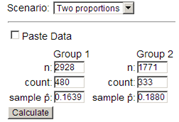
The Shargorodsky, Curhan, Curhan, and Eavey (2010) study from Investigation 1.14 actually focused on comparing the current hearing loss rate among teens (12-19 years) to previous years to see whether teen hearing loss is increasing, possibly due to heavier use of ear buds. In addition to the 1,771 participants in the NHANES 2005-6 study (333 with some level of hearing loss), they also had hearing loss data on 2,928 teens from NHANES III (1988-1994), with 480 showing some level of hearing loss. Our goal is to assess whether the difference between these two samples can be considered statistically significant.
Explain why it does not make sense to conclude that hearing loss was more prevalent in 1988-1994 than in 2005-2006 based only on the comparison that 480 > 333.
Suggest a better way to compare the prevalence of hearing loss between the two studies. Calculate one number as the statistic for this study (what symbols are you using?). Does your statistic seem large enough to convince you that there has been an increase in hearing loss?
\(\hat{p}_{88} - \hat{p}_{05}\) = 480/2928 - 333/1771 = -0.024 (judgements of the impressiveness of this number will vary; it seems on the small side but the sample sizes are large)
The simplest statistic for comparing a binary variable between two groups is the difference in the proportion of "successes" for each group. These proportions, calculated separately for each group rather than looking at the overall proportion, are called conditional proportions.
In this case, we compute the difference in the proportion of teens with some level of hearing loss between the two years \((\hat{p}_{94} - \hat{p}_{06} = 480/2928 - 333/1771)\text{.}\)
You can specify the counts from the two-way table, but you have to do so in "column format" (each row is a combination of the two variables and the counts are all in one column)
JMP creates a "Mosaic Plot" (the column widths also reflect the relative sample sizes). An extended two-way table is shown below the Mosaic Plot although the rows and columns are reversed. Click the red Contingency Table arrow and uncheck Col% and Total% to see a less cluttered table.
Do these data convince you that there is a difference in the population proportions? If not, what could be another explanation for the difference you see in these numerical and graphical summaries for these two samples?
As we’ve said before, it certainly is possible to obtain sample proportions this far apart, just by random chance, even if the population proportions (of teens with some hearing loss) were the same. The question now is how likely such a difference would be if the population proportions were the same.
We can answer this question by modeling the sampling variability, arising from taking independent random samples from these populations, for the difference in two sample proportions. Investigating this sampling variability will help us to assess whether this particular difference in sample proportions is strong evidence that the population proportions actually differ.
Let \(\pi_{94}\) represent the proportion of all American teenagers in 1994 with at least some hearing loss, and similarly for \(\pi_{06}\text{.}\) Define the parameter of interest to be \(\pi_{94} - \pi_{06}\text{,}\) the difference in the population proportions between these two years. State appropriate null and alternative hypotheses about this parameter to reflect the researchers’ conjecture that hearing loss by teens is becoming more prevalent.
Because the population sizes are very large compared to the sample sizes, we will model this by treating the populations as infinite and sampling from binomial processes.
So under the null hypothesis we really only have one value of \(\pi\) to estimate – the common population proportion with hearing loss for these two years.
Describe how you could carry out a simulation analysis to investigate whether the observed difference in sample proportions provides strong evidence that the population proportions with hearing loss differed between these two time periods. How will you estimate the p-value?
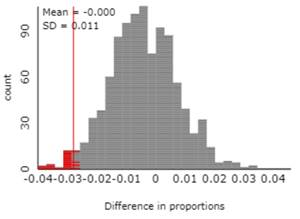
We could take random samples of 2928 and 1771 from two populations that have the same population proportion of successes. Then see how often 1 - 2 ≈ -0.024 when 94 - 06 = 0 by random sampling alone.
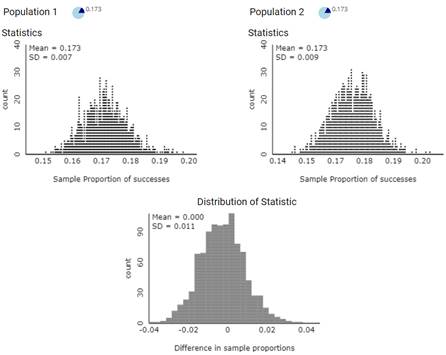
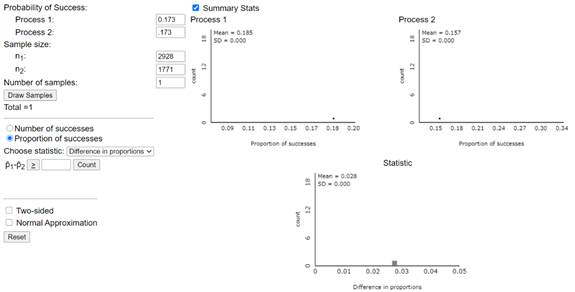
We will begin our simulation analysis by assuming the (common) population proportion is actually this value (\(\pi = 0.173\)). We simulate the drawing of two different random samples from this population, one to represent the 1994 study and the other for the 2006 study. Then we examine the distribution of the difference in the conditional proportions with some hearing loss between these two years. Finally, we repeat this random sampling process for many trials. [Note: We can assume \(\pi = 0.173\) without loss of generality, but you might want to verify this with other values for \(\pi\) as well.]
Describe the distribution of \(\hat{p}_1\) values, the distribution of \(\hat{p}_2\) values, and the distribution of \(\hat{p}_1 - \hat{p}_2\) values. Does the distribution of difference in proportions behave as you expected? In particular, does the mean of this distribution make sense? (How does it compare to the means of the individual \(\hat{p}\) distributions?) Explain.
Answers will vary but should expect the distributions of sample proportions (with large sample sizes) to each be approximately normal with means equal to the (same) population proportion and for the mean of the differences (assuming the null is true) to be close to zero.
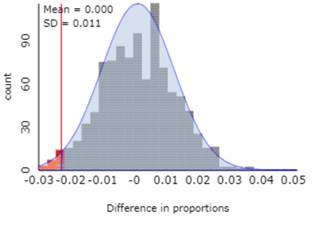
The distributions of the values should be approximately normal with means around 0.173. The standard deviations should be around 0.007 and 0.009. The distribution of the 1-2 values should be approximately normal with mean around 0 (0.173 - 0.173) and standard deviation around 0.011, which is larger than the individual distribution SDs.
Now determine the empirical p-value by counting how often the simulated difference in conditional proportions is at least as extreme as the actual value observed in the study by entering the observed value in the Count Samples box and pressing the Count button. (Make sure the direction matches the alternative hypothesis.)
This is a small p-value and provides moderate evidence against the null hypothesis in favor of the alternative hypothesis that the population proportion with at least some level of hearing loss was greater in 2006 than in 1994.
It turns out that there is no "exact" method for calculating the p-value here, because the difference in two binomial variables does not have a binomial, or any other known, probability distribution.
Check the Normal Approximation box to overlay a normal curve on your null distribution to evaluate whether the simulated differences appear to "line up" with observations from a standard normal distribution.
There is a theoretical result that the difference in two normal distributions will also follow a normal distribution. When our sample sizes (\(n_1\) and \(n_2\)) are large, we know the individual binomial distributions are well approximated by normal distributions. Consequently, the difference of the sample proportions will be well approximated by a normal distribution as well. The mean of this distribution is simply the difference in the means of the individual normal distributions.
Larger. This makes sense because we now have two sources of variability and the overall amount of variation will grow. (For example, we could get two extreme results, in opposite directions, and end up with a large difference.)
This makes sense because we now have two sources of variability and the overall amount of variation will grow. (For example, we could get two extreme results, in opposite directions, and end up with a large difference.)
When the null hypothesis is true, we are assuming \(\pi_1 = \pi_2\text{,}\) so we can substitute in the same number for both values. Otherwise, we can substitute in \(\hat{p}_1\) and \(\hat{p}_2\text{.}\)
Central Limit Theorem for the difference in two sample proportions.
When taking two independent samples (of sizes \(n_1\) and \(n_2\)) from large populations, the distribution of the difference in the sample proportions \((\hat{p}_1 - \hat{p}_2)\) is approximately normal with mean equal to \(\pi_1 - \pi_2\) and standard deviation equal to \(SD(\hat{p}_1 - \hat{p}_2) = \sqrt{\frac{\pi_1(1-\pi_1)}{n_1} + \frac{\pi_2(1-\pi_2)}{n_2}}\text{.}\)
Under the null hypothesis \(H_0: \pi_1 - \pi_2 = 0\text{,}\) the standard deviation simplifies to \(\sqrt{\pi(1-\pi)(\frac{1}{n_1} + \frac{1}{n_2})}\) where \(\pi\) is the common population proportion.
Technical Conditions: We will consider the normal model appropriate if the sample sizes are large, namely \(n_1\pi_1 > 5\text{,}\)\(n_1(1 - \pi_1) > 5\text{,}\)\(n_2\pi_2 > 5\text{,}\)\(n_2(1 - \pi_2) > 5\text{,}\) and the populations are large compared to the sample sizes.
Note: The variability in the differences in sample proportions is larger than the variability of individual sample proportions. In fact, the variances (standard deviation squared) add, and then we take the square root of the sum of variances to find the standard deviation.
However, to calculate these values we would need to know \(\pi_1\text{,}\)\(\pi_2\text{,}\) or \(\pi\text{.}\) So again we estimate the standard deviation of our statistic using the sample data.
When testing whether the null hypothesis is true, we are assuming the samples come from the same population, so we "pool" the two samples together to estimate the common population proportion of successes. That is, we estimate \(\pi\) by looking at the ratio of the total number of successes to the total sample size:
Use these theoretical results to suggest the general formula for a standardized statistic and a method for calculating a p-value to test \(H_0: \pi_1 - \pi_2 = 0\) (also expressed as \(H_0: \pi_1 = \pi_2\)) versus the alternative \(H_a: \pi_1 - \pi_2 < 0\) (or \(H_a: \pi_1 < \pi_2\)). (This is referred to as the two-sample z-test or two proportion z-test.)
Use technology (or refer to your previous applet results) to compute the p-value for this standardized statistic using the standard normal distribution (mean 0, SD 1) and compare it to your simulation results.
When calculating confidence intervals, we make no assumptions about the populations (for example, when we are not testing a particular null hypothesis but only estimating the parameter, we do not assume a common value for \(\pi\)). So we will use a different formula to approximate the standard deviation of \(\hat{p}_1 - \hat{p}_2\text{:}\)
Calculate (by hand) and interpret a 95% confidence interval to compare hearing loss of American teenagers in these two years. Is this confidence interval consistent with your test of significance? Why is it theoretically possible the interval would not be consistent with the test of significance?
We are 95% confident that the population proportion with at least some hearing loss in 2006 is 0.001 to 0.047 larger than the population proportion with at least some hearing loss in 1994. This interval is consistent with our test because all of the values are negative (we rejected zero as a plausible value for the difference in population proportions in favor of the alternative that the probability of hearing loss was now larger). Technically we should adjust this comparison for the one-sided nature of the significance test. For example, the two-sided p-value would be 0.034, so we expect zero to not be included in the confidence interval for any confidence level of 96.6% or less.
It is technically incorrect to say there has been a 0.15% to 4.67% increase in hearing loss from 1994 to 2006, because "percentage change" implies a multiplication of values, not an addition or subtraction as we are considering here. It would be acceptable to say that the increase is between 0.15 and 4.67 percentage points.
The above Central Limit Theorem holds when the populations are much larger than the samples (e.g., more than 20 times the sample size) and when the sample size is large. We will consider the latter condition met when we have at least 5 successes and at least 5 failures in each sample (so there are four numbers to check).
Note: A "Wilson adjustment" can be used with this confidence interval similar to the Plus Four Method from Chapter 1, this time putting one additional success and one additional failure in each sample. This adjustment will be most useful when the sample proportions are close to 0 or 1 (that is when the sample size conditions above are not met).
Summarize your conclusions from this study. Be sure to address statistical significance, statistical confidence, and the populations you are willing to generalize the results to. Also, are you willing to conclude that the change in the prevalence of hearing loss is due to the increased use of ear buds among teenagers between 1994 and 2006? Explain why or why not.
The change in the likelihood of some hearing loss in these two samples is statistically significant (p-value = 0.017 from z-test) and we are 95% confident that the population proportion is 0.001 to 0.047 higher "now" than before among all American teenagers (representative samples by NHANES).
We have moderate evidence against the null hypothesis (p-value \(\approx 0.02\text{,}\) meaning we would get a difference in sample proportions \(\hat{p}_1 - \hat{p}_2\) as small as \(-0.024\) or smaller in about 1.7% of random samples from two populations with \(\pi_1 = \pi_2\)). We are 95% confident that the population proportion with some hearing loss is between 0.0015 and 0.047 higher "now" than ten years ago. We feel comfortable drawing these conclusions about the populations the NHANES samples were selected from as they were random samples from each population (and there was no overlap in the populations between these two time periods). However, there are many things that have changed during this time period, and it would not be reasonable to attribute this increase in hearing loss exclusively to the use of ear buds.
Check the box to paste in 2 columns of data (stacked or unstacked) and press Use Data or specify the sample sizes and either the sample counts or the sample proportions and press Calculate.
For the test, check the box for Test of Significance. Keep the hypothesized difference at zero and set the direction of the alternative, press Calculate.
With raw data or after specifying the two-way table in column format, select Analyze > Fit Y by X and specify the categorical response variable (Y, Response) and the categorical explanatory variable (X, Factor)
(This works for raw data too, but be careful how you specify the explanatory and response variables and use "pooled estimate of variance." This reports the z-score as well.)
Note: Data are "stacked" if each column represents a different variable (e.g., year surveyed and hearing condition) and they are "unstacked" if each column represents a different group (e.g., 1998 and 2002).
In a follow-up study, Su & Chan (2017) examined hearing loss data for 1165 participants from the 2009-2010 National Health and Nutrition Examination Survey to see whether this trend has continued. They estimate the prevalence (after adjusting for a non-simple random sample and weighting the data to be representative of the population) of some hearing loss to be 0.152. If we treat this as a sample proportion, is this significantly different from the 2005-6 data?
In Practice Problem 1.1B, you considered data on the first 3 months of the Premier soccer league in 2019 (pre-Covid) and in 2020 (during Covid, when no fans were allowed). Consider these observations as random samples from independent processes. In 2019, the home team won 54 of the first 88 games and in 2020, the home team won 40 of 87 matches.
Specify appropriate null and alternative hypothesis, being clear how these hypotheses change from Chapter 1. Are you using a one-sided or two-sided alternative?
Use the Comparing Two Population Proportions applet to carry out a simulation. What are you using for the common probability of success? Which values do you count for the p-value? What do you conclude?
You should explore the individual \(\hat{p}\) distributions but most focus on the distribution of \(\hat{p}_1 - \hat{p}_2\text{,}\) including the mean, standard deviation, and whether the distribution behaves like a normal distribution.
In an empty Data window, select Cols > New Column. Name the column count1994, and specify 1 row. Create a formula and select Random > Random Binomial. Specify n = 2928 and p = 0.173. Press OK
Create a new column but specify 1000 as the number of rows and repeat the above commands. (After creating the first column, you can double click on a second column to activate it, and then right click to open the formula editor.)
Create a new column with a "conditional if" formula for diff \(\leq\) -0.024 ("true" or "false"). Then use Analyze > Distribution to tally this column.