So far you have focused on the distribution of the "number of successes" in repeated sampling from a random process. We will extend that exploration to the distribution of sample proportions, which is a traditional time to talk about the normal approximation for this distribution.
Manufacturers often perform "quality checks" to ensure that their manufacturing process is operating under certain specifications. Suppose a manager at Hershey’s is concerned that his manufacturing process is no longer producing the correct color proportions (orange, yellow, brown) in Reese’s candies.
Conjecture: A friend finds 10 orange candies in her bag. Does this convince you that the three colors are not equally likely? What other information would you want to know? What if she tells you these orange pieces were 50% of the candies in her bag?
Conjectures will vary. Knowing the total number of candies (sample size) is crucial. 10 out of 20 (50%) is much different from 10 out of 100 (10%). With 50% orange, this provides some evidence against equal proportions, but we would want more information about sampling variability.
Take a (presumably representative) sample of \(n = 25\) Reese’s Pieces candies and record the number of orange, yellow, and brown candies in your sample.
Define "success" to be an orange candy and "failure" to be a non-orange candy. Is it reasonable to treat these data as observations from a binomial process? Explain.
Yes, this is reasonably a binomial process: There are two possible outcomes (orange/not orange), a fixed number of trials (\(n = 25\)), the trials are independent (assuming sampling with replacement or from a very large population), and the probability of success (getting an orange candy) is constant for each trial. The main assumption to consider is whether the candies are well-mixed and randomly selected.
Prediction: Based on your data, do you think one-third is a plausible value for the probability Hershey’s process produces an orange candy? How are you deciding? What more information do you need?
Conjectures will vary. Students need more information about how much variability to expect in sample proportions when the true probability is one-third. A simulation will help determine whether the observed sample proportion is reasonably close to 1/3 or surprisingly far away.
Reporting the sample proportion as the statistic is often more informative than the sample count, but that means we need to know about the null distribution of sample proportions.
No, you typically get different numbers of orange candies. This demonstrates sampling variability—even when the true probability is 0.333, individual samples produce different results due to random chance.
Each dot represents the sample proportion of orange candies in one sample of 25 candies. The entire dotplot shows the distribution of sample proportions across many samples when the true probability is 0.333, illustrating the sampling distribution of the sample proportion.
Recall that for a binomial random variable, \(X\text{,}\) the expected value \(E(X) = n \times \pi\) and the standard deviation \(SD(X) = \sqrt{n \times \pi \times (1-\pi)}\text{.}\) It can also be shown that random variables follow these rules:
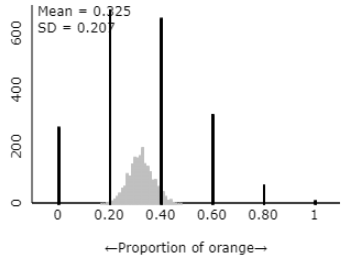
Prediction: If we had instead taken 2,000 samples of size \(n = 100\) candies, how do you think the distribution of the sample proportions would compare to the distribution where \(n = 25\text{?}\) Explain.
With \(n = 100\text{,}\) we would expect less variability in the sample proportions compared to \(n = 25\text{.}\) The distribution should still be centered at 0.333 and roughly symmetric, but with much less spread. Larger sample sizes lead to more precise estimates of the population parameter.
Describe the behavior (shape, center, variability) of this (new) distribution and how it has changed from the previous. Focus on the most substantial change in the distribution. Is this what you expected?
The center remains at approximately 0.333. The shape remains roughly symmetric and mound-shaped. The most substantial change is in variability: the distribution with \(n = 100\) has much less spread than the distribution with \(n = 25\text{.}\) This makes sense because larger sample sizes lead to less sampling variability.
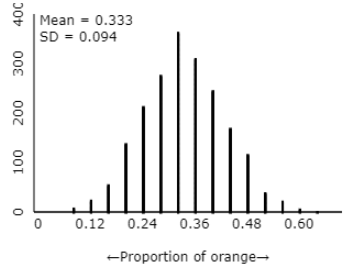
The distribution with \(n = 5\) has much more variability (SD ≈ 0.211) compared to \(n = 25\) (SD ≈ 0.094). The center remains at 0.333, but smaller sample sizes produce much more spread in the sample proportions.
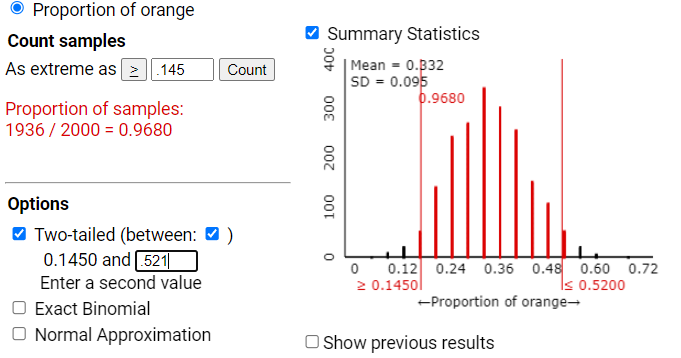
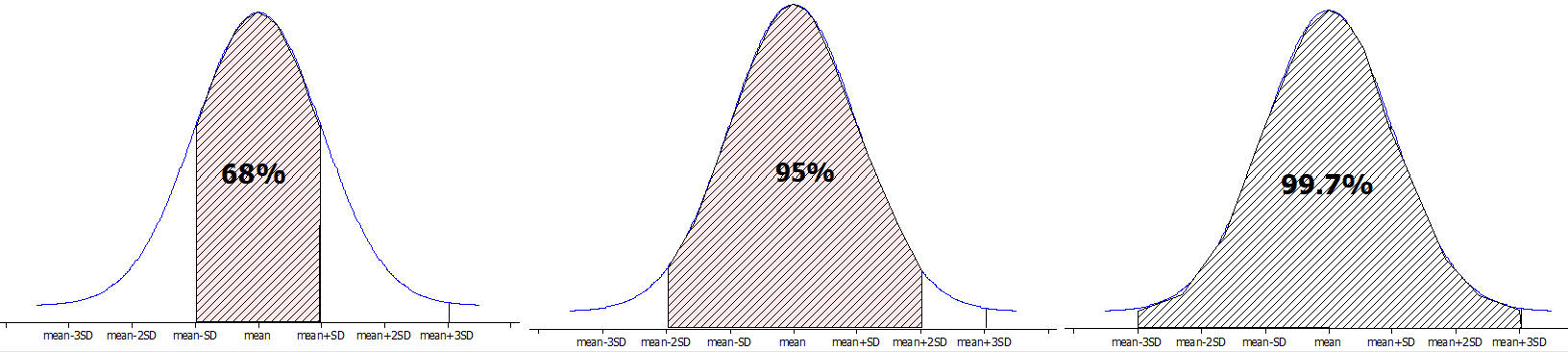
Return to the scenario where \(n = 25\) and \(\pi = 0.333\text{.}\) Earlier, you found that in this scenario \(E(\hat{p}) = 0.333\) and \(SD(\hat{p}) = 0.094\text{.}\) Calculate the following "cut-offs":
Approximately 95-96% of the samples have a sample proportion between 0.145 and 0.521 (within two standard deviations of 0.333). This percentage may vary slightly in different simulations due to random chance, but should consistently be close to 95%.
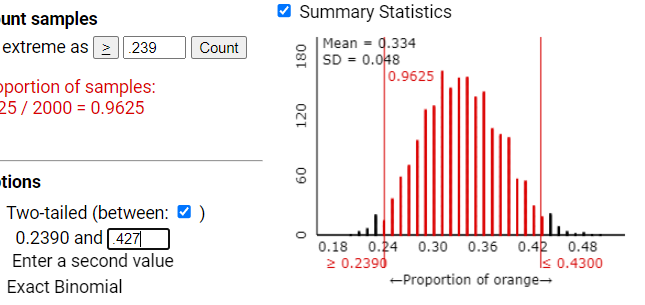
Repeat the previous two questions (calculating cut-offs and using the applet to find the percentage) for \(n = 100\) (including using the new SD and new cut-offs).
The percentage of samples within these cut-offs is still approximately 95%. While the standard deviation is smaller (less variability), the percentage within two standard deviations remains consistent regardless of sample size. This demonstrates that the empirical rule applies to the sampling distribution regardless of sample size.
Correct! The simulation results show that approximately 95% of the sample proportions fall within two standard deviations of the mean (0.333), which is consistent with the empirical rule’s prediction for mound-shaped, symmetric distributions.
No
Not quite. Look at the percentage of samples falling within two standard deviations - it should be close to 95%, which agrees with the empirical rule.
Solution.
Yes, the simulation results agree well with the empirical rule. Approximately 95% of the sample proportions fall within two standard deviations of the mean (0.333), which is consistent with the empirical rule’s prediction for mound-shaped, symmetric distributions.
Notice that if we know the value of \(\pi\) and we know the sample size \(n\text{,}\) we can predict the value of the sample proportion fairly precisely. This will be very helpful to us in deciding whether an observed sample proportion is "far away" from a hypothesized value for \(\pi\text{.}\)
With \(n = 25\) and \(π = 0.50\text{,}\) the standard deviation is \(\sqrt(0.50 × 0.50 / 25) = 0.10\text{.}\) Using the empirical rule, 95% of sample proportions should fall between 0.50 - 2(0.10) = 0.30 and 0.50 + 2(0.10) = 0.70.
An expert witness in a paternity suit testifies that the length (in days) of pregnancy (the time from conception to delivery of the child) is approximately normally distributed with mean \(\mu = 270\) days and standard deviation \(\sigma = 10\) days. The defendant in the suit is able to prove that he was out of the country during a period that began 280 days before the birth of the child and ended 230 days before the birth of the child.
If the defendant was the father of the child, what is the probability that the mother could have had the very long (more than 280 days) or the very short (less than 230 days) pregnancy indicated by the testimony?