Recognize that inference procedures for paired data use the same one-sample \(t\)-procedures as in the previous section, and that these procedures are applied to the differences of the paired observations.
In the previous edition of this textbook, we found that Amazon prices were, on average, lower than those of the UCLA Bookstore for UCLA courses in 2010. It’s been several years, and many stores have adapted to the online market, so we wondered, how is the UCLA Bookstore doing today?
We sampled 201 UCLA courses. Of those, 68 required books that could be found on Amazon. A portion of the data set from these courses is shown in Table 7.2.1, where prices are in U.S. dollars.
Each textbook has two corresponding prices in the data set: one for the UCLA Bookstore and one for Amazon. Therefore, each textbook price from the UCLA bookstore has a natural correspondence with a textbook price from Amazon. When two sets of observations have this special correspondence, they are said to be paired.
Two sets of observations are paired if each observation in one set has a special correspondence or connection with exactly one observation in the other data set.
To analyze paired data, it is often useful to look at the difference in outcomes of each pair of observations. In the textbook data set, we look at the differences in prices, which is represented as the diff variable. Here, for each book, the differences are taken as
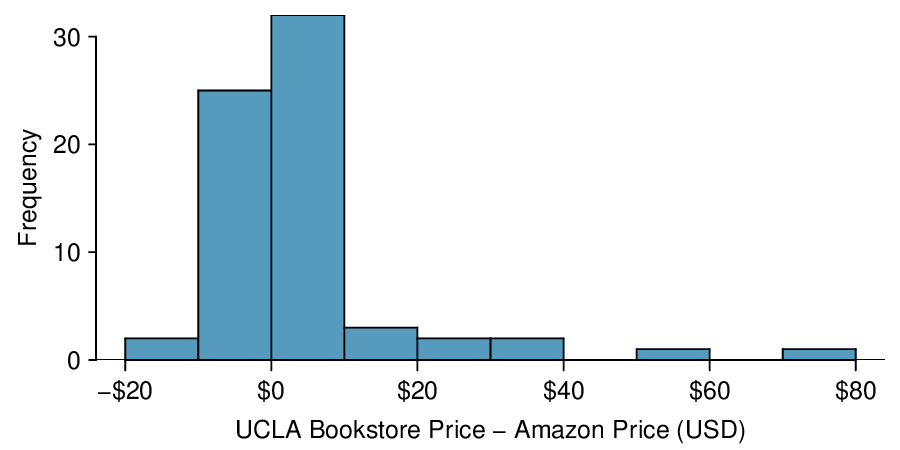
It is important that we always subtract using a consistent order; here Amazon prices are always subtracted from UCLA prices. A histogram of these differences is shown in Figure 7.2.2. Using differences between paired observations is a common and useful way to analyze paired data.
The first difference shown in Table 7.2.1 is computed as: \(47.97 - 47.45 = 0.52\text{.}\) What does this difference tell us about the price for this textbook on Amazon versus the UCLA bookstore? 1
The difference is taken as UCLA Bookstore price - Amazon price. Because the difference is positive, it tells us that the UCLA Bookstore price was greater for this textbook. In fact, it was $0.52, or 52 cents, more expensive at the UCLA bookstore than on Amazon.
We will set up and implement a hypothesis test to determine whether, on average, there is a difference in textbook prices between Amazon and the UCLA bookstore. We are considering two scenarios: there is no difference in prices or there is some difference in prices.
\(\mu_{\text{diff}}=0\text{.}\) On average, there is no difference in textbook prices.
Can the \(t\)-distribution be used for this application? The observations are based on a random sample from a large population, so independence is reasonable. While the distribution of the data is very strongly skewed, we do have \(n = 68\) observations. This sample size is large enough that we do not have to worry about whether the population distribution for difference in price might be nearly normal or not. Because the conditions are satisfied, we can use the \(t\)-distribution to this setting.
We compute the standard error associated with \(\bar{x}_{\text{diff}}\) using the standard deviation of the differences (\(s_{\text{diff}} = 13.42\)) and the number of differences (\(n_{\text{diff}} = 68\)):
Next we compute the test statistic. The point estimate is the observed value of \(\bar{x}_{\text{diff}}\text{.}\) The null value is the value hypothesized under the null hypothesis. Here, the null hypothesis is that the true mean of the differences is 0.
\begin{gather*}
T = \frac{\text{ point estimate } - \text{ null value } } {SE \text{ of estimate } } = \frac{3.58- 0}{1.63} = 2.20
\end{gather*}
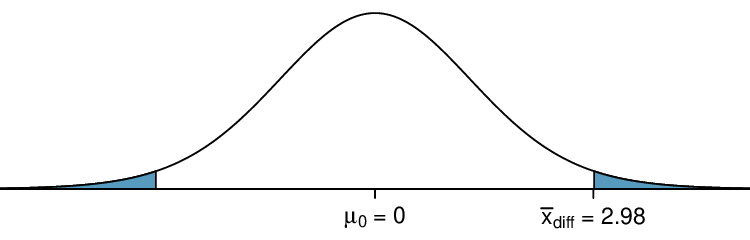
The degrees of freedom are \(df = 68 - 1 = 67\text{.}\) To visualize the p-value, the sampling distribution of \(\bar{x}_{\text{diff}}\) is drawn as though \(H_0\) is true. This is shown in Figure 7.2.5. Because this is a two-sided test, the p-value corresponds to the area in both tails. Using statistical software, we find the area in the tails to be 0.0312.
Because the p-value of 0.0312 is less than 0.05, we reject the null hypothesis. We have evidence that, on average, there is a difference in textbook prices. In particular, we can say that, on average, Amazon prices are lower than the UCLA Bookstore prices for UCLA course textbooks.
No. The fact that Amazon is, on average, less expensive, does not imply that it is less expensive for every textbook. Examining the distribution shown in Figure 7.2.2, we see that there are certainly a handful of cases where Amazon prices are much lower than the UCLA Bookstore’s, which suggests it is worth checking Amazon or other online sites before purchasing. However, in many cases the Amazon price is above what the UCLA Bookstore charges, and most of the time the price isn’t that different.
For reference, this is a very different result from what we (the authors) had seen in a similar data set from 2010. At that time, Amazon prices were almost uniformly lower than those of the UCLA Bookstore’s and by a large margin, making the case to use Amazon over the UCLA Bookstore quite compelling at that time.
Check: Check conditions for the sampling distribution of \(\bar{x}_{\text{diff}}\) to be nearly normal.
Independence: Data come from one random sample (with paired data) or from a randomized matched pairs experiment. When sampling without replacement, check that the sample size is less than 10% of the population size.
Lar: ge sample or normal population: \(n_{\text{diff}}\ge 30\) or population of diffs is nearly normal. If the number of differences is less than 30 and the distribution of the population of differences is unknown, check for strong skew or outliers in the sample differences. If neither is found, then the condition that the population of differences is nearly normal is considered reasonable.
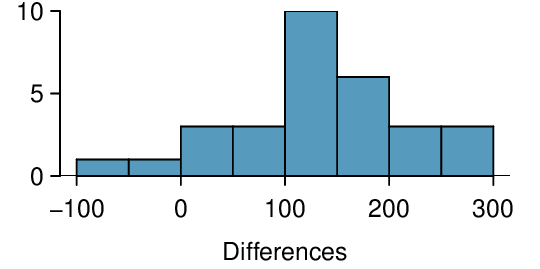
An SAT preparation company claims that its students’ scores improve by over 100 points on average after their course. A consumer group would like to evaluate this claim, and they collect data on a random sample of 30 students who took the class. Each of these students took the SAT before and after taking the company’s course, so we have a difference in scores for each student. We will examine these differences \(x_1=57\text{,}\)\(x_2=133\text{,}\) ..., \(x_{30}=140\) as a sample to evaluate the company’s claim. The distribution of the differences, shown in Figure 7.2.8, has a mean of 135.9 and a standard deviation of 82.2. Do these data provide convincing evidence to back up the company’s claim? Use the five step framework to organize your work.
Check: We have a random sample of students and have paired data on them. We will assume that this sample of size 30 represents less than 10% of the total population of such students. Finally, the number of differences is \(n_{\text{diff}}=30 \ge 30\text{,}\) so we can proceed with the 1-sample \(t\)-test.
Conclude: p-value \(=0.012 \lt \alpha\) so we reject the null hypothesis. The data provide convincing evidence to support the company’s claim that students’ scores improve by more than 100 points, on average, following the class.
Because we found evidence to support the company’s claim, does this mean that a student will score more than 100 points higher on the SAT if they take the class than if they do not take the class? 2
No. First, this is an observational study, so we cannot make a causal conclusion. Maybe SAT test takers tend to improve their score over time even if they don’t take this SAT class. Secondly, students’ scores improved by more than 100 points on average. That does not imply that each student improved by more than 100 points. With a sample standard deviation of 82.2 and a mean of 135.9, some students did worse after the SAT class. This can be verified by Figure 7.2.13
Subsection7.2.4Confidence intervals for the mean of a difference
In the previous examples, we carried out a matched pairs \(t\)-test, where the null hypothesis was that the true average of the paired differences is zero. Sometimes we want to estimate the true average of paired differences with a confidence interval, and we use a 1-sample \(t\)-interval with paired data. Consider again the table summarizing data on: UCLA Bookstore price \(-\) Amazon price, for each of the 68 books sampled.
We construct a 95% confidence interval for the average price difference between books at the UCLA Bookstore and on Amazon. Conditions have already verified, namely, that we have paired data from a random sample and that the number of differences is at least 30. We must find the critical value, \(t^{\star}\text{.}\) Since \(df = 67\) is not on the \(t\)-table, round the \(df\) down to 60 to get a \(t^{\star}\) of 2.00 for 95% confidence. (See Subsection 7.2.5 for how to get a more precise interval using a calculator.) Plugging the \(t^{\star}\) value, point estimate, and standard error into the confidence interval formula, we get:
We are 95% confident that the UCLA bookstore is, on average, between $0.33 and $6.83 more expensive than Amazon for UCLA course books. This interval does not contain zero, so it is consistent with the earlier hypothesis test that rejected the null hypothesis that the average difference was 0. Because our interval is entirely above 0, we have evidence that the true average difference is greater than zero. Unlike the hypothesis test, the confidence interval gives us a good idea of how much more expensive the UCLA bookstore might be, on average.
No. This interval is attempting to estimate the average difference with 95% confidence. It is not attempting to capture 95% of the values. A quick look at Figure 7.2.2 shows that much less than 95% of the differences fall between $0.32 and $6.84.
Check: Check conditions for the sampling distribution of \(\bar{x}_{\text{diff}}\) to be nearly normal.
Independence: Data come from one random sample (with paired data) or from a randomized matched pairs experiment. When sampling without replacement, check that the sample size is less than 10% of the population size.
Large sample or normal population: \(n_{\text{diff}}\ge 30\) or population of diffs is nearly normal. - If the number of differences is less than 30 and the distribution of the population of differences is unknown, check for strong skew or outliers in the sample differences. If neither is found, then the condition that the population of differences is nearly normal is considered reasonable.
Conclude: Interpret the interval and, if applicable, draw a conclusion in context.
We are C% confident that the true mean of the differences in [...] is between and . If applicable, draw a conclusion based on whether the interval is entirely above, is entirely below, or contains the value 0.
An SAT preparation company claims that its students’ scores improve by over 100 points on average after their course. A consumer group would like to evaluate this claim, and they collect data on a random sample of 30 students who took the class. Each of these students took the SAT before and after taking the company’s course, so we have a difference in scores for each student. We will examine these differences \(x_1=57\text{,}\)\(x_2=133\text{,}\) ..., \(x_{30}=140\) as a sample to evaluate the company’s claim. The distribution of the differences, shown in Figure 7.2.13, has a mean of 135.9 and a standard deviation of 82.2. Construct a confidence interval to estimate the true average increase in SAT after taking the company’s course. Is there evidence at the 95% confidence level that students score an average of more than 100 points higher after the class? Use the five step framework to organize your work.
Identify: The parameter we want to estimate is \(\mu_{\text{diff}}\text{,}\) the true change in SAT score after taking the company’s course. Here, \({\text{diff}}\) = \({\text{ SAT score after course } - \text{ SAT score before course } }\text{.}\) We will estimate this parameter at the 95% confidence level.
Choose: Because we have paired data and the parameter to be estimated is a mean of differences, we will use a 1-sample \(t\)-interval with paired data.
Check: We have a random sample of students with paired observations on them. We will assume that these 30 students represent less than 10% of the total number of such students. Finally, the number of differences is \(n_{\text{diff}}=30\ge 30\text{,}\) so we can proceed with the 1-sample \(t\)-interval.
We find \(t^{\star}\) for the one sample case using the \(t\)-table at row \(df = n -1\) and confidence level C%. For a 95% confidence level and \(df = 30 - 1 = 29\text{,}\)\(t^{\star} = 2.045\text{.}\)
Conclude: We are 95% confident that the true average increase in SAT score following the company’s course is between 105.2 points to 166.6 points. There is sufficient evidence that students score greater than 100 points higher, on average, after the company’s course because the entire interval is above 100.
Based on the interval (105.2, 166.6), calculated previously, can we say that 95% of student scores increased between 105.2 and 166.6 points after taking the company’s course? 3
No. This interval is attempting to capture the average increase. It is not attempting to capture 95% of the increases. Looking at Figure 7.2.8, we see that only a small percent had increases between 105.2 and 166.6.
In our UCLA textbook example, we had 68 paired differences. Because \(df=67\) was not on our \(t\)-table, we rounded the \(df\) down to 60. This gave us a 95% confidence interval (0.325, 6.834). Use a calculator to find the more exact 95% confidence interval based on 67 degrees of freedom. How different is it from the one we calculated based on 60 degrees of freedom? 4
Choose TInterval or equivalent. We do not have all the data, so choose Stats on a TI or Var on a Casio. Enter x\(= 3.58\) and Sx\(= 13.42\text{.}\) Let n\(= 68\) and C-Level\(= 0.95\text{.}\) This should give the interval (0.332, 6.828). The intervals are equivalent when rounded to two decimal places.
Paired data can come from a random sample or a matched pairs experiment. With paired data, we are often interested in whether the difference is positive, negative, or zero. For example, the difference of paired data from a matched pairs experiment tells us whether one treatment did better, worse, or the same as the other treatment for each subject.
We use the notation \(\bar{x}_{\text{diff}}\) to represent the mean of the sample differences. Likewise, \(s_{\text{diff}}\) is the standard deviation of the sample differences, and \(n_{\text{diff}}\) is the number of sample differences.
To carry out inference on paired data, we first find all of the sample differences. Then, we perform a one-sample procedure using the differences. For this reason, the confidence interval and hypothesis test with paired data use the same one-sample \(t\)-procedures, where the degrees of freedom is given by \(n_{\text{diff}}-1\text{.}\)
The one-sample \(t\)-interval and and \(t\)-test with paired data require the sampling distribution for \(\bar{x}_{diff}\) to be nearly normal. For this reason, we must check that the following conditions are met.
Independence: Data should come from one random sample (with paired observations) or from a randomized matched pairs experiment. If sampling without replacement, check that the sample size is less than 10% of the population size.
Large sample or normal population: \(n_{\text{diff}}\ge 30\) or population of differences nearly normal. If the number of differences is less than 30 and it is not known that the population of differences is nearly normal, we argue that the population of differences could be nearly normal if there is no strong skew or outliers in the sample differences.
When the conditions are met, we calculate the confidence interval and the test statistic as we did in the previous section. Here, our data is a list of differences.
Confidence interval: \(\text{ point estimate } \ \pm\ t^{\star} \times SE\ \text{ of estimate }\)
Air quality measurements were collected in a random sample of 25 country capitals in 2013, and then again in the same cities in 2014. We would like to use these data to compare average air quality between the two years. Should we use a paired or non-paired test? Explain your reasoning.
Paired, data are recorded in the same cities at two different time points. The temperature in a city at one point is not independent of the temperature in the same city at another time point.
Consider two sets of data that are paired with each other. Each observation in one data set has a natural correspondence with exactly one observation from the other data set.
Consider two sets of data that are paired with each other. Each observation in one data set is subtracted from the average of the other data set’s observations.
Since it’s the same students at the beginning and the end of the semester, there is a pairing between the datasets, for a given student their beginning and end of semester grades are dependent.
Since the subjects were sampled randomly, each observation in the men’s group does not have a special correspondence with exactly one observation in the other (women’s) group.
Since it’s the same subjects at the beginning and the end of the study, there is a pairing between the datasets, for a subject student their beginning and end of semester artery thickness are dependent.
Since it’s the same subjects at the beginning and the end of the study, there is a pairing between the datasets, for a subject student their beginning and end of semester weights are dependent.
In each of the following scenarios, determine if the data are paired.
We would like to know if Intel’s stock and Southwest Airlines’ stock have similar rates of return. To find out, we take a random sample of 50 days, and record Intel’s and Southwest’s stock on those same days.
We randomly sample 50 items from Target stores and note the price for each. Then we visit Walmart and collect the price for each of those same 50 items.
A school board would like to determine whether there is a difference in average SAT scores for students at one high school versus another high school in the district. To check, they take a simple random sample of 100 students from each high school.
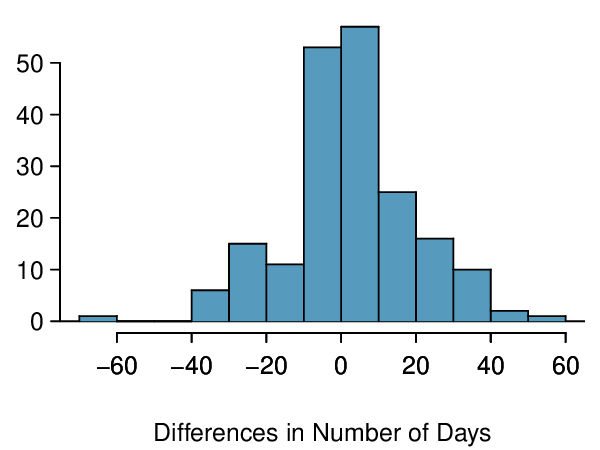
Let’s consider a limited set of climate data, examining temperature differences in 1948 vs 2018. We randomly sampled 197 locations from the National Oceanic and Atmospheric Administration’s (NOAA) historical data, where the data was available for both years of interest. We want to know: were there more days with temperatures exceeding 90°F in 2018 or 1948? 5
The difference in number of days exceeding 90°F (number of days in 2018 - number of days in 1948) was calculated for each of the 197 locations. The average of these differences was 2.9 days with a standard deviation of 17.2 days. We are interested in determining whether these data provide strong evidence that there were more days in 2018 that exceeded 90°F from NOAA’s weather stations.
Based on the results of this hypothesis test, would you expect a confidence interval for the average difference between the number of days exceeding 90°F from 1948 and 2018 to include 0? Explain your reasoning.
For each observation in one data set, there is exactly one specially corresponding observation in the other data set for the same geographic location. The data are paired.
\(H_{0}: \mu_{diff} = 0\) (There is no difference in average number of days exceeding 90°F in 1948 and 2018 for NOAA stations.) \(H_{A}: \mu_{diff} \neq 0\) (There is a difference.)
Locations were randomly sampled, so independence is reasonable. The sample size is at least 30, so we’re just looking for particularly extreme outliers: none are present (the observation off left in the histogram would be considered a clear outlier, but not a particularly extreme one). Therefore, the conditions are satisfied.
\(SE = 17.2/ \sqrt{197} = 1.23\text{.}\)\(T = \frac{2.9-0}{1.23} = 2.36\) with degrees of freedom \(df = 197-1 = 196\text{.}\) This leads to a p-value of about 0.019.
Since the p-value is less than 0.05, we reject \(H_{0}\text{.}\) The data provide strong evidence that NOAA stations observed more 90°F days in 2018 than in 1948.
Type 1 Error, since we may have incorrectly rejected \(H_{0}\text{.}\) This error would mean that NOAA stations did not actually observe a decrease, but the sample we took just so happened to make it appear that this was the case.
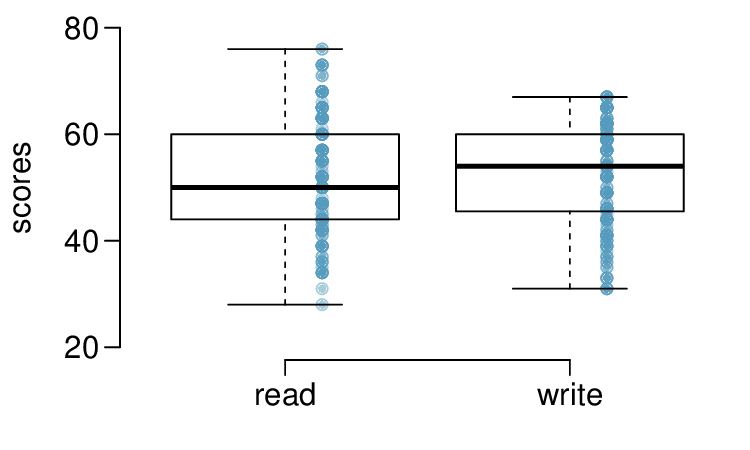
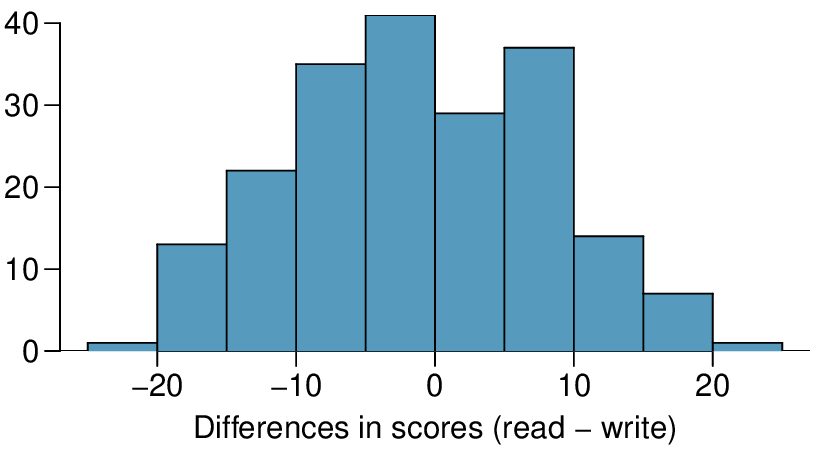
The National Center of Education Statistics conducted a survey of high school seniors, collecting test data on reading, writing, and several other subjects. Here we examine a simple random sample of 200 students from this survey. Side-by-side box plots of reading and writing scores as well as a histogram of the differences in scores are shown below.
Create hypotheses appropriate for the following research question: is there an evident difference in the average scores of students in the reading and writing exam?
The average observed difference in scores is \(\bar{x}_{read-write} = -0.545\text{,}\) and the standard deviation of the differences is 8.887 points. Do these data provide convincing evidence of a difference between the average scores on the two exams?
Based on the results of this hypothesis test, would you expect a confidence interval for the average difference between the reading and writing scores to include 0? Explain your reasoning.
We considered the change in the number of days exceeding 90°F from 1948 and 2018 at 197 randomly sampled locations from the NOAA database in Exercise 7.2.7.5. The mean and standard deviation of the reported differences are 2.9 days and 17.2 days. Calculate a 90% confidence interval for the average difference between number of days exceeding 90°F between 1948 and 2018. Does the confidence interval provide convincing evidence that there were more days exceeding 90°F in 2018 than in 1948 at NOAA stations? Include all steps of the Identify, Choose, Check, Calculate, Conclude framework.
Identify: we want to estimate the average difference in number of days exceeding 90°F for (2018-1948) with 90% confidence. Choose: 1-sample tinterval with paired data. Check \(n_{diff}=197 \ge 30\) and the locations are randomly sampled. Calculate: average \(SE_{diff}=1.23\) and \(df=196\text{.}\)\(t^{*} \approx 1.65\text{.}\)\(2.9 \pm 1.65 \times 1.23 \rightarrow (0.87, 4.93)\text{.}\) Conclude: We are 90% confident that there was an increase of 0.87 to 4.93 in the average difference of days that hit 90°F in 2018 relative to 1948 for NOAA stations. We have evidence that the average difference of days that hit 90°F increased, because the interval is entirely above 0.
We considered the differences between the reading and writing scores of a random sample of 200 students who took the High School and Beyond Survey in Exercise 7.2.7.6. The mean and standard deviation of the differences are \(\bar{x}_{read-write} = -0.545\) and 8.887 points.
Calculate a 95% confidence interval for the average difference between the reading and writing scores of all students.