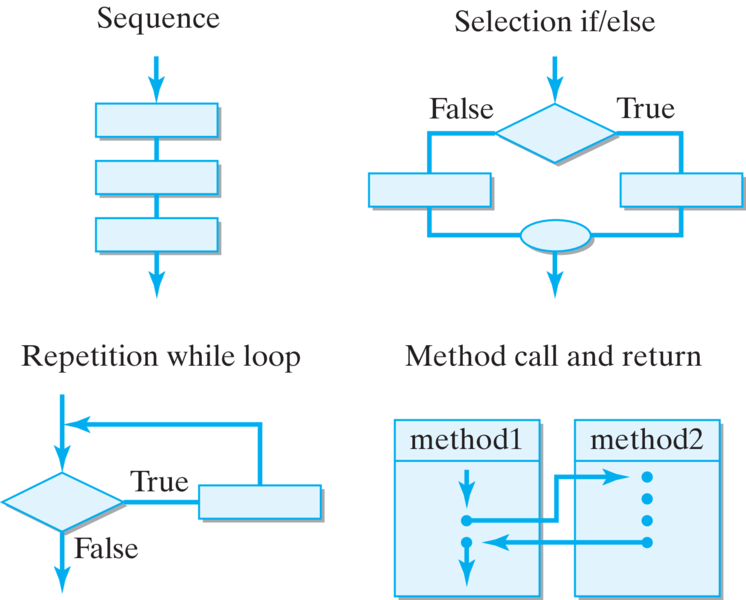
Structured programming is the practice of writing programs that are built up from a small set of predefined control structures. As an overall approach to programming, structured programming has largely been superseded by the object-oriented approach. Nevertheless, its design principles are still relevant to the design of the algorithms and methods that make up a program’s objects.
The principles of structured programming seem so obvious today that it may be difficult to appreciate their importance. In the 1960s and 1970s, one of the main controls used in programs was the infamous go to statement, which could be used to transfer control of a program to any arbitrary location within it, and from there to any other arbitrary location, and so on. This led to incredibly complex and ill-formed programs—so called “spaghetti code” —that were almost impossible to understand and modify.
Structured programming evolved in reaction to the unstructured software development practices of the 1960s, which were fraught with budget overruns, costly delays, and failed products. One of the classic research results of that era was a 1966 paper by Boehm and Jacopini that showed that any program using go to’s could be represented by an equivalent program that used a sequence of two types of controls: if/else and while structures. Another influential paper by Edgar Dikjstra ( “GoTo Statement Considered Harmful” ) pointed out the various ways in which the go to statement could lead to impossibly complex programs.
The Pascal language, introduced by Nicklaus Wirth in 1971, was designed to promote structured programming techniques and became the language of choice within academic institutions because of its suitability as a teaching language. In Pascal, the go to was replaced with the four structures that control the flow of execution in a program ( Figure 6.11.1):
The Java language supplies us with a good collection of control structures, and Java’s syntax constrains the way we can use them. One of the features of the four control structures is that each has a single entry point and exit ( Figure 6.11.1). This is an extremely important property. To grasp its importance, consider the following debugging problem:
k = 0; // 1. Unstructured code
System.out.println("k= " + k);// 2. k should equal 0 here
goto label1; // 3.
label2:
System.out.println("k= " + k);// 4. k should equal 1 here
In this example a goto statement is used to jump to label1, a label that marks a section of code somewhere else in the program. Suppose we’re trying to determine how k has acquired an erroneous value and that its value is correct in line 2 of this sequence. Given the go to statement on line 3, there’s no guarantee that control will ever return to the println() statement on line 4. Thus, in unstructured code it is very difficult to narrow the scope of an error to a fixed segment of code. Because the go to statement can transfer control anywhere in the program, with no guarantee of return, any segment of code can have multiple entry points and multiple exits.
k = 0; // 1. Structured code
System.out.println("k= " + k); // 2. k should equal 0 here
someMethod(); // 3.
System.out.println("k= " + k); // 4. k should equal 1 here
In this case, we can be certain that control will eventually return to line 4. If k’s value is erroneous on line 4, we can trace through someMethod() to find the error. Because any segment of a structured program has a single entry and exit, we can use a pair of println() statements in this way to converge on the location of the program bug.
An important implication of the single-entry/single-exit property is that we can use preconditions and postconditions to help us design and debug our code. The previous example provided a simple example: The precondition is that k should equal 0 on line 2, and the postcondition is that k should equal 1 on line 4. Figure 6.11.2 shows some additional examples.
int k = 0; // Precondition: k == 0
k = 5; // Assignment to k
// Postcondition: k == 5
\(\bullet\)
int k = 0; // Precondition: k == 0
while (k < 100) { // While loop
k = 2 * k + 2;
}
// Postcondition: k >= 100
\(\bullet\)
/*
* factorial(n):
* factorial(n) is 1 if n is 0
* factorial(n) is n * n-1 * n-2 * ... * 1 if n > 0
* Precondition: n >= 0
* Postcondition:
* factorial(n) = 1 if n = 0
* = n * n-1 * n-2 * ... * 1 if n > 0
*/
public int factorial(int n) {
if (n == 0)
return 1;
else {
int f = 1; // Init a temporary variable
for (int k = n; k >= 1; k--) // For n down to 1
f = f * k; // Accumulate the product
return f; // Return the factorial
} // else
} // factorial()
Figure6.11.2.Using pre- and postconditions to document code.
In the first example, we use pre- and postconditions to define the semantics of an assignment statement. No matter what value k has before the assignment, the execution of the assignment (k = 5) will make the postcondition (k == 5) true.
In the second example, the postcondition follows from the semantics of the while loop. Because the loop-entry condition is k < 100, when the loop exits the postcondition (k >= 100) must be true.
The third example shows how pre- and postconditions can be used to design and document methods. The factorial(n) is defined for \(n \geq 0\) as follows:
factorial(n) is 1, if n == 0
factorial(n) is n * n-1 * n-2 * ... * 1, if n > 0
In other words, the factorial of N is defined as the cumulative product of multiplying 1 times 2, times 3, and so on up to N. For example, if N is 5, then factorial(5) is 1 * 2 * 3 * 4 * 5 = 120.
Note how the factorial computation is done in the method. The variable f, which is used to accumulate the product, is initialized to 1. Then on each iteration of the for loop, f is multiplied by k and the product is assigned back to f. This is similar to the way we accumulate a sum, except in this case we are accumulating a product.
The precondition on the factorial() method represents the condition that must be true in order for the method to work correctly. Factorial is undefined for \(n \lt 0\text{,}\) so it is important that n be greater than or equal to 0 whenever this method is called. Given that the precondition holds, the postcondition gives a precise specification of what must be true when the method is finished.
The pre- and postconditions for a method can be used to design defensive code —that is, code that guards against errors. For example, what action should factorial() take if its precondition fails to hold? In Java, the best way to handle this situation is to throw an IllegalArgumentException, as the following example illustrates:
public int factorial(int n) {
if (n < 0) // Precondition failure
throw new IllegalArgumentException("Factorial:"+ n);
if (n == 0)
return 1;
else {
int f = 1; // Init a temporary variable
for (int k = n; k >= 1; k--) // For n down to 1
f = f * k; // Accumulate the product
return f; // Return the factorial
}} // factorial()
An exception is an erroneous condition (an error) that arises during the running of a program. An Exception is an object that encapsulates information about the erroneous condition. A program can throw an Exception, thereby stopping the program, when an erroneous condition is detected. In this example, we create a new IllegalArgumentException that would report the illegal value of n with something like the following error message:
Exception in thread "main" java.lang.IllegalArgumentException:
Factorial: -1
at Test.factorial(Param.java:5)
at Test.main(Param.java:18)
You have undoubtedly already encountered thrown exceptions during program development. Java has an extensive hierarchy of Exception s, which we will cover in some depth in Chapter 11. For now, however, we just note how to use the IllegalArgumentException. As its name implies, an IllegalArgumentException is used when an argument in a method call is not legal.
Rather than continuing the program with an erroreous data value, throwing an exception causes the program to stop and print an error message. Determining whether an argument is legal or illegal is an important use of the method’s preconditions. The failure of the precondition in factorial() points to a problem elsewhere in the program, because it is doubtful that the program deliberately passed a negative value to factorial(). The discovery of this error should lead to modifications in that part of the program where factorial() was invoked—perhaps to some validation of the user’s input:
The use of preconditions and postconditions in the ways we’ve described can help improve a program’s design at several distinct stages of its development:
Design stage: Using pre- and postconditions in design helps to clarify the design and provides a precise measure of correctness.
Implementation and testing stage: Test data can be designed to demonstrate that the preconditions and postconditions hold for any method or code segment.
Debugging stage: Using the pre- and postconditions provides precise criteria that can be used to isolate and locate bugs. A method is incorrect if its precondition is true and its postcondition is false. A method is improperly invoked if its precondition is false.
Like other programming skills and techniques, learning how to use pre- and postconditions effectively requires practice. One way to develop these skills is to incorporate pre- and postconditions into the documentation of the methods you write for laboratories and programming exercises. Appendix A provides guidelines on how to incorporate pre- and postconditions into your program’s documentation. However, it would be a mistake to get in the habit of leaving the identification of pre- and postconditions to the documentation stage. The method’s documentation, including its pre- and postconditions, should be developed during the design stage and should play a role in all aspects of program development.
What we’re really saying here is that using pre- and postconditions forces you to analyze your program’s logic. It is not enough to know that a single isolated statement within a program works correctly at the present time. You have to ask yourself: Will it continue to work if you change some other part of the program? Will other parts of the program continue to work if you revise it? No matter how clever you are, it is not possible to keep an entire model of a good-sized program in your head at one time. It is always necessary to focus on a few essential details and leave aside certain others. Ideally, what you hope is that the details you’ve left aside for the moment aren’t the cause of the current bug you’re trying to fix. Using pre- and postconditions can help you determine the correctness of the details you choose to set aside.
Principle6.11.3.EFFECTIVE DESIGN: Pre- and Postconditions.
Pre- and postconditions are an effective way of analyzing the logic of your program’s loops and methods. They should be identified at the earliest stages of design and development. They should play a role in the testing and debugging of the program. Finally, they should be included, in a systematic way, in the program’s documentation.
As the programs you write become longer and more complex, the chances that they contain serious errors increase dramatically. There’s no real way to avoid this complexity. The only hope is to try to manage it. In addition to analyzing your program’s structure, another important aspect of program design is the attempt to reduce its complexity.
Perhaps the best way to reduce complexity is to build your programs using a small collection of standard structures and techniques. The basic control structures ( Figure 6.11.1) help reduce the potential complexity of a program by constraining the kinds of branching and looping structures that can be built. The control structures help to manage the complexity of your program’s algorithms. In the same way, the following practices can help reduce and manage the complexity in a program.
Principle6.11.6.PROGRAMMING TIP: Standard Techniques.
Acquire and use standard programming techniques for standard programming problems. For example, using a temporary variable to swap the values of two variables is a standard technique.
Instead of reinventing the wheel, use library classes and methods whenever possible. These have been carefully designed by experienced programmers. Library code has been subjected to extensive testing.