
14.4. Plan 3: Get a soup from multiple URLs¶
14.4.1. Plan 3: Example¶
Sometimes we want to get information from multiple web pages that have the same layout. For example, all of the UMSI faculty pages have the same general design.
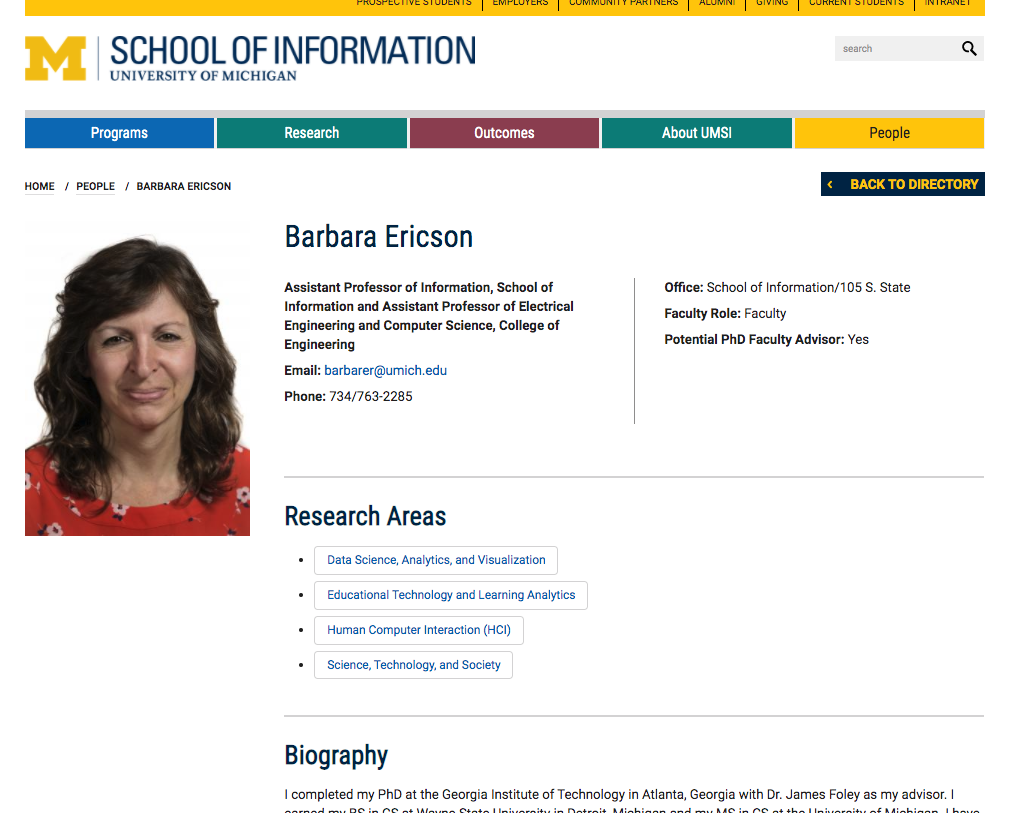
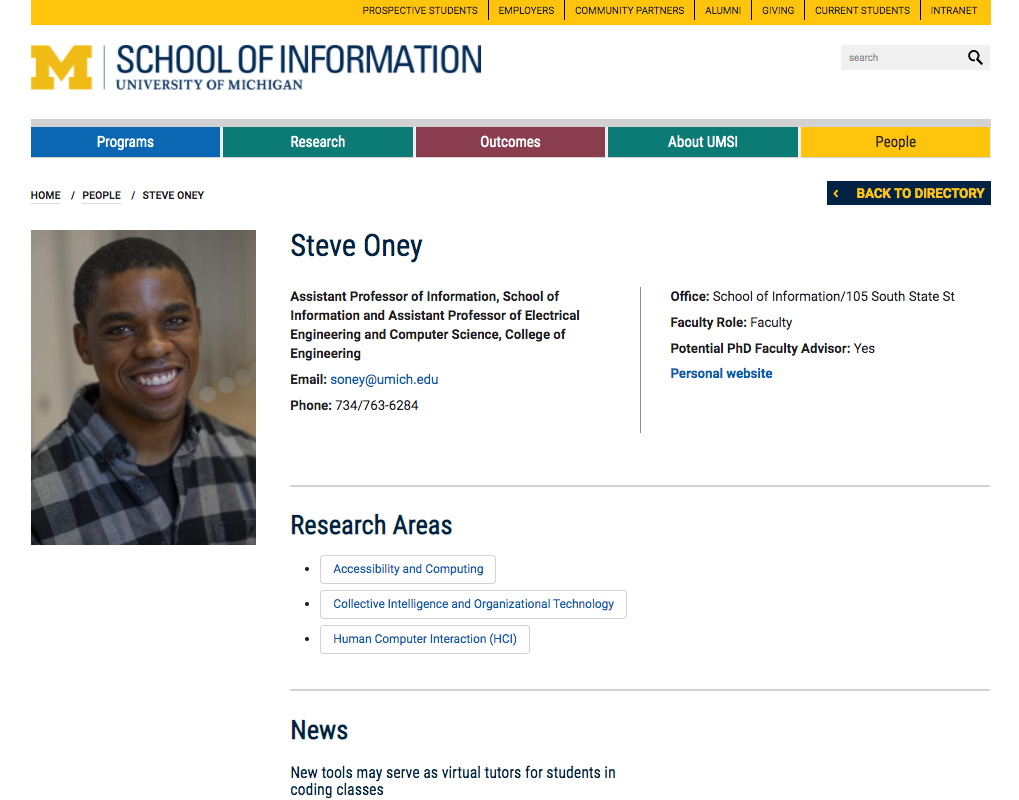
We are interested in getting information about mutliple UMSI professors: Dr. Barb Ericson, Dr. Steve Oney, and Dr. Paul Resnick.
Their webpages are:
https://web.archive.org/web/20230128074139/https://www.si.umich.edu/people/
https://web.archive.org/web/20230128074139/https://www.si.umich.edu/people/
https://web.archive.org/web/20230128074139/https://www.si.umich.edu/people/
In this code, we get a soup from multiple UMSI faculty pages.
Goal: Get a soup from multiple webpages
# Load libraries for web scraping
from bs4 import BeautifulSoup
import requests
# Get a soup from multiple URLs
base_url = 'https://web.archive.org/web/20230128074139/https://www.si.umich.edu/people/'
endings = ['barbara-ericson', 'steve-oney', 'paul-resnick']
for ending in endings:
url = base_url + ending
r = requests.get(url)
soup = BeautifulSoup(r.content, 'html.parser')14.4.2. Plan 3: When to use this plan¶
Use this plan when you want to scrape the same thing from multiple webpages.
14.4.3. Plan3: How to use this plan¶
Look at the webpages you want to scrape and determine which parts they have in common, and which parts are different. The parts that they have in common are the base_url. The parts that are different are the endings.
14.4.4. Plan 3: Exercises¶
If you want to also get the link to the most recent news item from Dr Robin Brewer’s page, how would you change the code below? Her web page is https://web.archive.org/web/20230110174202/https://www.si.umich.edu/people/robin-brewer.
Change the code and run it to see if you’re right!