
5.3. La búsqueda secuencial¶
Cuando los ítems de datos se almacenan en una colección, por ejemplo en una lista, decimos que tienen una relación lineal o secuencial. Cada ítem de datos se almacena en una posición relativa a los demás. En las listas de Python, estas posiciones relativas son los valores de los índices de los ítems individuales. Dado que estos valores de los índices están ordenados, es posible para nosotros visitarlos en secuencia. Este proceso da lugar a nuestra primera técnica de búsqueda, la búsqueda secuencial.
La Figura 1 muestra cómo funciona esta búsqueda. Comenzando en el primer ítem de la lista, simplemente nos trasladamos de un ítem a otro, siguiendo el orden secuencial subyacente hasta que encontremos lo que buscamos o nos quedemos sin ítems. Si nos quedamos sin ítems, hemos descubierto que el ítem que estábamos buscando no estaba presente.
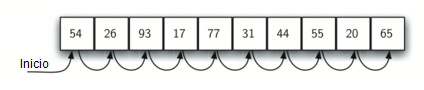
Figura 1: Búsqueda secuencial en una lista de enteros¶
Figura 1: Búsqueda secuencial en una lista de enteros
La implementación en Python para este algoritmo se muestra en el CodeLens 1. La función necesita la lista y el ítem que estamos buscando y devuelve un valor booleano que indica si el ítem está o no presente. La variable booleana encontrado se inicializa en False y se le asigna el valor True si descubrimos el ítem en la lista.
Activity: CodeLens Búsqueda secuencial en una lista no ordenada (search1)
5.3.1. Análisis de la búsqueda secuencial¶
Para analizar los algoritmos de búsqueda, tenemos que tomar una decisión sobre una unidad básica de cálculo. Recuerde que éste es típicamente el paso común que debe repetirse para resolver el problema. Para buscar, tiene sentido contar el número de comparaciones realizadas. Cada comparación puede o no descubrir el ítem que estamos buscando. Además, aquí hacemos otra suposición. La lista de ítems no está ordenada de ninguna manera. Los ítems se han colocado al azar en la lista. En otras palabras, la probabilidad de que el ítem que estamos buscando esté en una posición determinada es exactamente la misma para cada posición de la lista.
Si el ítem no está en la lista, la única manera de saberlo es compararlo con cada ítem presente. Si hay \(n\) ítems, entonces la búsqueda secuencial requiere \(n\) comparaciones para descubrir que el ítem no está allí. En el caso de que el ítem sí esté en la lista, el análisis no es tan sencillo. En realidad hay tres escenarios diferentes que pueden ocurrir. En el mejor de los casos encontraremos el ítem en el primer lugar que miramos, al principio de la lista. Sólo necesitaremos una comparación. En el peor de los casos, no descubriremos el ítem hasta la última comparación, la n-ésima comparación.
¿Cómo sería el caso promedio? En promedio, encontraremos el ítem alrededor de la mitad de la lista; es decir, compararemos contra \(\frac{n}{2}\) ítems. Recordemos, sin embargo, que a medida que n se hace grande, los coeficientes, sean cuales sean, se vuelven insignificantes en nuestra aproximación, por lo que la complejidad de la búsqueda secuencial es \(O(n)\). La Tabla 1 resume estos resultados.
Caso |
Mejor caso |
Peor caso |
Caso promedio |
|---|---|---|---|
El ítem está presente |
\(1\) |
\(n\) |
\(\frac{n}{2}\) |
El ítem no está presente |
\(n\) |
\(n\) |
\(n\) |
Supusimos anteriormente que los ítems en nuestra colección habían sido colocados aleatoriamente de modo que no hubiera orden relativo entre ellos. ¿Qué pasaría con la búsqueda secuencial si los ítems estuvieran ordenados de alguna manera? ¿Seríamos capaces de mejorar en algo la eficiencia en nuestra técnica de búsqueda?
Suponga que la lista de ítems se construyó de modo que los ítems estuvieran en orden ascendente, de menor a mayor. Si el ítem que estamos buscando está presente en la lista, la posibilidad de que esté en alguna de las n posiciones sigue siendo la misma que antes. Aún tendremos que hacer el mismo número de comparaciones para encontrar el ítem. Sin embargo, si el ítem no está presente hay una ligera ventaja. La Figura 2 muestra este proceso a medida que el algoritmo busca el ítem 50. Observe que los ítems aún se comparan en secuencia hasta el 54. No obstante, en este punto, sabemos algo más. No sólo el 54 no es el ítem que estamos buscando, sino que ningún otro ítem más allá de 54 servirá ya que la lista está ordenada. En este caso, el algoritmo no tiene que seguir mirando a lo largo de todos los ítems para reportar que no se encontró el elemento. Puede detenerse inmediatamente. El CodeLens 2 muestra esta variación de la función de búsqueda secuencial.
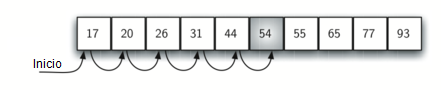
Figura 2: Búsqueda secuencial en una lista ordenada de enteros¶
Figura 2: Búsqueda secuencial en una lista ordenada de enteros
Activity: CodeLens Búsqueda secuencial en una lista ordenada (search2)
La Tabla 2 resume estos resultados. Note que en el mejor de los casos podríamos descubrir que el ítem no está en la lista mirando únicamente un ítem. En promedio, lo sabremos solamente después de mirar \(\frac{n}{2}\) ítems. Sin embargo, esta técnica sigue siendo \(O(n)\). En resumen, una búsqueda secuencial se mejora ordenando la lista sólo en caso que no encontremos el ítem.
El ítem está presente |
\(1\) |
\(n\) |
\(\frac{n}{2}\) |
El ítem no está presente |
\(1\) |
\(n\) |
\(\frac{n}{2}\) |
Autoevaluación
- 5
- Con cinco comparaciones obtendría el segundo 18 en la lista.
- 10
- No es necesario buscar en toda la lista, solo hasta que usted encuentre la clave que está buscando.
- 4
- No, recuerde que en una búsqueda secuencial usted empieza desde el principio y revisa cada clave hasta que encuentre lo que busque o la lista se agote.
- 2
- En este caso sólo se necesitaron 2 comparaciones para encontrar la clave.
Q-3: Suponga que usted está realizando una búsqueda secuencial en la lista [15, 18, 2, 19, 18, 0, 8, 14, 19, 14]. ¿Cuántas comparaciones necesitaría hacer para encontrar la clave 18?
- 10
- No es necesario buscar en toda la lista, ya que está ordenada, usted puede detener la búsqueda cuando haya comparado contra un valor mayor que la clave.
- 5
- Dado que 11 es menor que el valor clave 13, usted debe seguir buscando.
- 7
- Puesto que 14 es mayor que el valor clave 13, usted puede detener la búsqueda.
- 6
- Ya que 12 es menor que el valor clave 13, usted debe seguir buscando.
Q-4: Suponga que usted está realizando una búsqueda secuencial en la lista ordenada [3, 5, 6, 8, 11, 12, 14, 15, 17, 18]. ¿Cuántas comparaciones necesitaría hacer para encontrar la clave 13?