
13.5. Different Base A and B, M - 1 match over cols Aid(D),Bid(M)¶
In this example, we still consider this part of the database represented by this fragment of the conceptual schema, but now we take note that there is one other pair of columns that could be matched: test_townID of Achievement and origin_townId of Skill.

We can ask an English query that will give us a slightly fewer number of rows (as you might expect it to in most shapes like this).
Find each Achievement with its Skill data where the Skill was achieved in the same town that it originated in.
Or rephrased to more closely match what will be in the result relation:
Find each Achievement with its same skillCode, same test_townId as origin_townId Skill data.
Logic to use in decision-making process for chart formulation:
The above stated English query uses Achievement and Skill as the two input relations and they still have different bases.
Indeed, the relationship circumstance is also the same: M-1, non-symmetric, implying the half-house symbol with Achievement as the A (M,peak) relation and Skill as the B (1, lower end) relation.
The difference is the ‘works on’ columns are different, because along with matching on skillCode, we are adding an exact match on the test_townId of Achievement to the origin_townId of Skill. This makes the works-on situation in the Match Join symbol different, as shown below. The skillCode, test_townID columns are different than Achievement’s identifier, and since skillCode identifies Skill, the skillCode, origin_townID columns comprise of more than Skill’s identifier. So the Match Join symbol contains Aid(D): skillCode, origin_townID and Bid(E): skillCode, origin_townID.
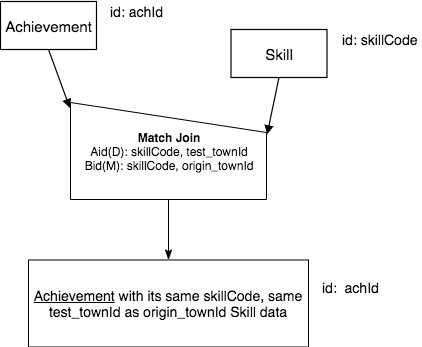
Result relation name and base: note that as with the previous example, the base of the result relation is the same as the A relation (Achievement in this case). When we use more columns to match over, we now add a new phrase “same skillCode, same test_townId as origin_townId” after the words “with its”.
Tip
This pattern of naming the result and determining its base can be used in all of these M-1 A-B situations:
A with its same-col (or same col-in-A as col-in-B) B data.
The SQL query examples change in two ways: we eliminate one more column in the reduce, since we are matching over 2 columns, and we add another equality check to the filter portion in the WHERE clause. The traditional and the inner join examples in the first and second tabs are the alternatives (we cannot use natural join syntax any more).
achId |
creatureId |
skillCode |
proficiency |
achDate |
test_townId |
|---|---|---|---|---|---|
1 |
1 |
A |
3 |
2020-07-24 21:37:53 |
a |
2 |
1 |
E |
3 |
2017-09-15 15:35:00 |
d |
3 |
1 |
A |
3 |
2018-07-14 14:00:00 |
a |
4 |
1 |
E |
3 |
2020-07-24 21:37:53 |
d |
5 |
5 |
Z |
6 |
2016-04-12 15:42:30 |
t |
6 |
3 |
Z |
4 |
2018-07-15 00:00:00 |
be |
7 |
3 |
Z |
4 |
2018-07-15 00:00:00 |
be |
8 |
3 |
Z |
4 |
2018-07-15 00:00:00 |
be |
9 |
4 |
Z |
3 |
2018-06-10 00:00:00 |
a |
10 |
11 |
PK |
10 |
1998-08-15 00:00:00 |
le |
11 |
12 |
PK |
10 |
2016-05-24 00:00:00 |
le |
12 |
13 |
PK |
10 |
2012-08-06 00:00:00 |
le |
13 |
8 |
PK |
1 |
NULL |
t |
14 |
9 |
THR |
10 |
2018-08-12 14:30:00 |
mv |
15 |
10 |
THR |
10 |
2018-08-12 14:30:00 |
mv |
16 |
7 |
B2 |
19 |
2017-01-10 16:30:00 |
d |
17 |
9 |
B2 |
19 |
2017-01-10 16:30:00 |
d |
18 |
4 |
TR4 |
85 |
2012-07-30 00:00:00 |
le |
19 |
5 |
TR4 |
85 |
2012-07-30 00:00:00 |
le |
20 |
2 |
TR4 |
85 |
2012-07-30 00:00:00 |
le |
21 |
1 |
TR4 |
85 |
2012-07-30 00:00:00 |
le |
22 |
9 |
D3 |
8 |
2020-07-24 16:37:53 |
sw |
23 |
13 |
D3 |
8 |
2020-07-24 16:37:53 |
sw |
24 |
7 |
D3 |
8 |
2020-07-24 16:37:53 |
sw |
skillCode |
skillDescription |
maxProficiency |
minProficiency |
origin_townId |
|---|---|---|---|---|
A |
float |
10 |
-1 |
b |
B2 |
2-crew bobsledding |
25 |
0 |
d |
C2 |
2-person canoeing |
12 |
1 |
t |
D3 |
Australasia debating |
10 |
1 |
NULL |
E |
swim |
5 |
0 |
b |
O |
sink |
10 |
-1 |
b |
PK |
soccer penalty kick |
10 |
1 |
le |
THR |
three-legged race |
10 |
0 |
g |
TR4 |
4x100 meter track relay |
100 |
0 |
be |
U |
walk on water |
5 |
1 |
d |
Z |
gargle |
5 |
1 |
a |
13.5.1. Considering NULL values¶
Let’s look at the Skill data again:
skillCode |
skillDescription |
maxProficiency |
minProficiency |
origin_townId |
|---|---|---|---|---|
A |
float |
10 |
-1 |
b |
B2 |
2-crew bobsledding |
25 |
0 |
d |
C2 |
2-person canoeing |
12 |
1 |
t |
D3 |
Australasia debating |
10 |
1 |
NULL |
E |
swim |
5 |
0 |
b |
O |
sink |
10 |
-1 |
b |
PK |
soccer penalty kick |
10 |
1 |
le |
THR |
three-legged race |
10 |
0 |
g |
TR4 |
4x100 meter track relay |
100 |
0 |
be |
U |
walk on water |
5 |
1 |
d |
Z |
gargle |
5 |
1 |
a |
Notice that in one row, the origin_townId in Skill is a pesky NULL value. In databases, NULL cannot be matched to anything. It is important to understand that the Skill whose SkillCode is D3, Australasia debating, will never be able to appear in the result relation for this query. There are not any NULL test_townId values in Achievement in this data, but if there were, those rows would not appear in the result relation either.
13.5.2. Exercise¶
Try creating the precedence chart for this query.
English Query:
Find each Achievement with its same creatureId, same test_townId as reside_townId Creature data.